by Jason Fealy
Introduction
The number of systems that churn out data is ever-increasing and since kdb+ is at the core of the KX data solution stack, there is a substantial requirement to ensure interoperability between KX and other technologies.
In this blog post, we will demonstrate how to interface kdb+ with the Kafka REST proxy by leveraging the HTTP capability of kdb+. We will publish and consume data to/from Kafka and perform some simple administrative actions. The techniques described in the blog are also applicable to other RESTful APIs. We will also provide a very high-level overview of a simple Kafka data pipeline and touch on some native Kafka properties.
The Kafka REST proxy allows developers not only to produce and consume data to/from a Kafka cluster with minimal prerequisites but also perform some administrative tasks such as overwriting offset commits or manually assigning partitions to consumers via simple HTTP requests, without the need to leverage native clients.
What is Kafka
At its lowest level, Kafka is a pub-sub messaging system, but such is the functionality layered on top of this, it is more appropriate to describe Kafka as a distributed streaming platform. Kafka is also highly horizontally scalable with both fault tolerance and high availability.
Basic Features
- Kafka clusters consist of numerous servers acting as brokers which decouple the producers and consumers.
- Producer processes publish messages to topics within the Kafka cluster.
- Topics can consist of numerous partitions, which are immutable and ordered commit logs.
- Messages can be partitioned based on the message key, ensuring all messages with the same key end up in the same partition, or in the case of a null key, messages are distributed on a round-robin basis across available partitions. Custom partitioning is also possible.
- Partitions are usually replicated across numerous brokers to provide fault tolerance.
- Consumer processes that subscribe to topics and are responsible for ingesting and processing the messages.
- Multiple consumer processes can be grouped together into a consumer group.
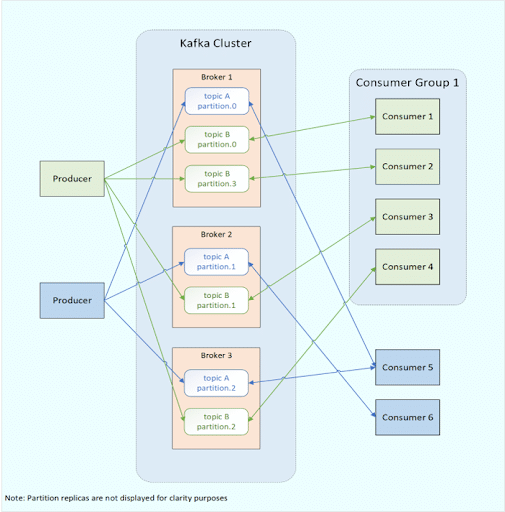
Fig 1: Simple Kafka System
KX kfk Library
KX systems provide the kfk library as part of the Fusion for kdb+ interface collection. The kfk library is a thin wrapper around the librdkafka C API for Kafka. Further information and examples on using this interface can be found in Sergey Vidyuk’s blog post. In order to allow other languages to interface with Kafka, which are not yet supported by existing clients, Confluent provides a REST proxy for the Kafka cluster. The purpose of this blog is to demonstrate how kdb+ can interact with Kafka via the REST proxy.
What is REST
REST (REpresentional State Transfer) is an architectural style for API design. APIs which adhere to the six formal architectural constraints are said to be RESTful. A RESTful system exposes information about itself in terms of its resources and allows clients perform certain operations on these resources e.g. creation, mutation, deletion. It’s important to note that REST and HTTP are not the same thing. Systems which use other transfer protocols can still be considered RESTful, however, HTTP is by far the most common protocol used by RESTful systems. The Kafka REST proxy is a HTTP based proxy.
Kafka REST Proxy
The Kafka REST proxy is an independent server process which resides in the Kafka cluster usually on its own machine. The proxy sits in between producer/consumer clients and the Kafka brokers, thereby providing a RESTful interface to the clients. The proxy acts as a producer or consumer depending on the type of API call e.g. POST, GET, DELETE. These API calls are then translated into native Kafka calls and relayed to the brokers. This enables almost any language which supports HTTP and string manipulation to talk to Kafka, thereby extending the usability of Kafka far beyond its natively supported clients. The Kafka REST API supports interactions with the cluster such as producing/consuming messages and accessing metadata such as topic lists and consumer offsets.
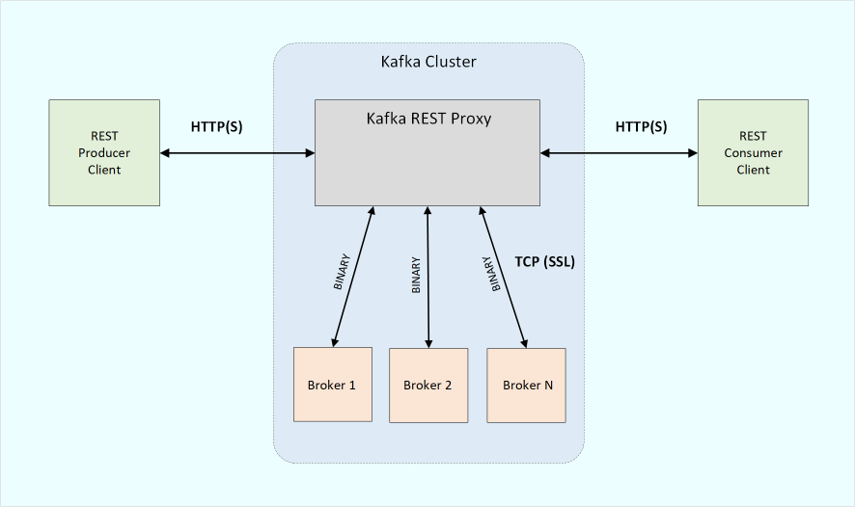
Fig 2: Kafka REST Proxy
Depending on the required operation, a call made from a client to the REST API will contain some or all of the following:
- Resource URL
- HTTP header(s)
- Payload
The HTTP headers used with the REST proxy are specific to Kafka and indicate the three properties of the data:
- The serialization format: At the time of writing, JSON is the only format supported by Kafka.
- The version of the API.
- The serialization of the data which is being produced/consumed and embedded in the body of the payload. There are currently three supported formats for the embedded data:
- base64 encoded strings
- Avro
- JSON
The header, therefore, takes the form of:
application/vnd.kafka.<embedded_format>.<api_version>+<serialization_format>For the purposes of this blog, we will embed the data as base64 encoded strings. Therefore, the full header takes the form of:
application/vnd.kafka.binary.v2+jsonSince kdb+ V3.6 2018.05.18, a built-in function exists to encode data to base64, namely .Q.btoa, however we need to define a custom function to decode from base64.
base64decode:{c:sum x="=";neg[c]_"c"$raze 1_'256 vs'64 sv'69,'0N 4#.Q.b6?x}It should be noted that the embedded format can be omitted when there are no embedded messages included in the payload e.g. for metadata requests. The above string will be used for Content-Type & Accept header fields where necessary.
As shown in Fig. 2, communication between the REST clients and the proxy is via HTTP. Communication between the proxy and the Kafka cluster is via TCP. SSL can also be configured.
HTTP and kdb+
Kdb+ has built-in helper functions for communication over HTTP, namely .Q.hp (HTTP POST) and .Q.hg (HTTP GET), however they aren’t comprehensive enough. In order to interact fully with the Kafka REST API, users need to be able to specify additional HTTP methods such as DELETE, pass in custom headers and payloads where necessary. The req function below is based on .Q.hmb, which underpins .Q.hp/hg, but allows users to specify the HTTP method and pass in custom headers. A payload message is provided as a string and the Content-length header will be generated from this. An empty list should be passed in situations where there is no payload.
k)req:{[url;method;hd;bd]d:s,s:"\r\n";url:$[10=@url;url;1_$url];p:{$[#y;y;x]}/getenv`$_:\("HTTP";"NO"),\:"_PROXY";u:.Q.hap@url;t:~(~#*p)||/(*":"\:u 2)like/:{(("."=*x)#"*"),x}'","\:p 1;a:$[t;p:.Q.hap@*p;u]1;(4+*r ss d)_r:(`$":",,/($[t;p;u]0 2))($method)," ",$[t;url;u 3]," HTTP/1.1",s,(s/:("Connection: close";"Host: ",u 2),((0<#a)#,$[t;"Proxy-";""],"Authorization: Basic ",.Q.btoa a),($[#hd;(!hd),'": ",/:. hd;()])),($[#bd;(s,"Content-length: ",$#bd),d,bd;d])}The req function takes 4 parameters:
- Resource URL
- HTTP method
- Dictionary of headers
- Message body as JSON object
Publishing and Consuming with kdb+
The following example will demonstrate how to produce and consume data to/from a Kafka topic. The Kafka cluster will run a single broker on port 9092. The REST proxy will run on port 8082. The default broker behavior enables automatic creation of a Kafka topic on the server (auto.create.topics.enable = true). When a topic is auto-created the default number of partitions is 1 (num.partitions =1). These configs can be changed but for the purposes of this example they will be left untouched.
Basic kdb+ REST Producer
Producing data to a Kafka topic is relatively straightforward. A HTTP POST request is made to the topic URL and the topic will be created automatically. The payload is a JSON array of objects named records. The raw kdb+ data will be first serialized to IPC bytes using -18! and then embedded as base64 encoded strings. Serializing to compressed IPC bytes is efficient and preserves datatype but it works on the assumption that any consumer is a q process. As mentioned previously, we could also embed the data as JSON by using .j.j. The records array can contain both key and value fields but for simplicity in this example, we will omit the key and embed the data under the value object. The HTTP response will be a JSON object which includes information such as the partition the message was placed in and the message offset within that partition.
q)`:data set data:flip`longCol`floatCol`dateCol`timeCol`stringCol`boolCol`symCol!5?/:(10;10f;.z.D;.z.T;0N 3#.Q.a;0b;`2);
q)
q)buildPayload:{"{\"records\":[{\"value\":\"",x,"\"}]}"};
q)topicURL:"http://localhost:8082/topics/data"
q)producerHeaders:("Content-Type";"Accept")!("application/vnd.kafka.binary.v2+json";"application/vnd.kafka.v2+json");
q)
q)// Publish data to the REST proxy
q)req[topicURL;`POST;producerHeaders;]buildPayload .Q.btoa`char$-18!data
"{\"offsets\":[{\"partition\":0,\"offset\":0,\"error_code\":null,\"error\":null}],\"key_schema_id\":null,\"value_schema_id\":null}"The entire table was published as a batch and as shown in the response, the message has a single offset within the partition log.
Basic kdb+ REST Consumer
Consuming data via the REST API requires a little bit more set up. First, a POST request is made to the consumer group URL with a payload which will include the consumer instance name, the format of the embedded data and some consumer instance settings. The response from this request will be a JSON object containing a base URI which will be used for all subsequent requests. A second POST request is made to the subscription URL with a payload containing the topic name. Finally, to consume data, a GET request is made to the records URL. The response JSON object will contain the data.
q)consumerGroupURL:"http://localhost:8082/consumers/myConsumerGroup";
q)header:enlist["Content-Type"]!enlist"application/vnd.kafka.v2+json";
q)
q)// the format here must match the embedded format specified in the producer API call
q)consumerSettings:(`name`format`auto.offset.reset)!(`myConsumer`binary`earliest);
q)
q)// create the consumer instance & deserialize the JSON response into a dictionary
q)postResponse:.j.k req[consumerGroupURL;`POST;header;.j.j consumerSettings];
q)
q)baseURI:postResponse`base_uri;
q)subcriptionURL:baseURI,"/subscription";
q)recordsURL:baseURI,"/records";
q)
q)// subscribe to the topic 'data'
q)req[subcriptionURL;`POST;header;"{\"topics\":[\"data\"]}"];
q)
q)consumerHeaders:enlist["Accept"]!enlist"application/vnd.kafka.binary.v2+json";
q)
q)// perform a GET request in order to fetch data from the topic specified in the subscribe request
q)records:req[recordsURL;`GET;consumerHeaders;""]; // no payload so pass empty list
q)
q)// decode the base64 encoded data, cast to bytes & deserialize
q)consumedData:-9!`byte$base64decode first(.j.k records)`value;
q)
q)// show that data consistency is maintained
q)(get`:data)~consumedData
1bAdditional functionality of Kafka REST API
If a consumer instance has been idle for some time, subsequent requests may return a HTTP error code 40403. This indicates the server cannot find the consumer instance.
q)req[recordsURL;`GET;consumerHeaders;""]
"{\"error_code\":40403,\"message\":\"Consumer instance not found.\"}"The instance may have been idle for longer than the consumer.instance.timeout.ms property (default 5min). This property can be overwritten if required. The consumer instance will have been destroyed and that can be confirmed by running the following command:
$ /bin/kafka-consumer-groups --bootstrap-server localhost:9092 --describe -group myConsumerGroup
Consumer group 'myConsumerGroup' has no active members.The consumer instance will need to be recreated. Further GET requests can then be performed to the topic. If multiple GET requests are performed in quick succession, it’s possible that some responses may be empty.
q)// recreate the consumer instance
q)req[consumerGroupURL;`POST;header;.j.j consumerSettings];
q)
q)// resubscribe to the topic 'data'
q)req[subcriptionURL;`POST;header;"{\"topics\":[\"data\"]}"];
q)
q)// send an initial consume GET request
q)records1:req[recordsURL;`GET;consumerHeaders;""];
q)
q)flip .j.k records1 // 1. the response indicates the consumed message is at offset 0 in the partition
topic | "data" ..
key | ..
value | "AQAAADIBAABiAGMLAAcAAABsb25nQ29sAGZsb2F0Q29sAGRhdGVDb2w..
partition| 0 ..
offset | 0 ..
q)
q)// 2 .send a GET request to determine the last committed offset for the consumer instance
q)req[baseURI,"/offsets";`GET;header;.j.j(enlist`partitions)!enlist enlist(`topic`partition!(`data;0))]
"{\"offsets\":[]}"
q)
q)// 3. send a second consume GET request
q)req[recordsURL;`GET;consumerHeaders;""]
"[]"
q)
q)// 4. send a another GET request to check committed offsets
q)first value .j.k req[baseURI,"/offsets";`GET;header;.j.j(enlist`partitions)!enlist enlist(`topic`partition!(`data;0))]
topic partition offset metadata
--------------------------------
"data" 0 1 ""In the above code the following occurred:
- The initial GET request consumed the message at offset 0 in partition 0.
- The consumer instance advanced its own position by 1 upon consuming that message but did not commit that offset.
- The second GET request returned an empty response as the consumer attempted to read from offset 1 in the partition but no data was produced to the topic in the meantime.
- On the second GET request, the consumer committed the offset which was returned from the previous poll (enable.auto.commit has a default value of true). Any consumers which are assigned that partition will read from that offset.
In order to reprocess these records again, the REST API provides functionality to seek to an offset of our choosing. It is possible to seek to the beginning of the partition and reprocess all records.
q)// send a POST request to seek to the first offset for that partition
q)req[baseURI,"/positions/beginning";`POST;header;.j.j(enlist`partitions)!enlist enlist(`topic`partition!(`data;0))];
q)
q)// perform the GET request again
q)flip .j.k req[recordsURL;`GET;consumerHeaders;""]
topic | "data" ..
key | ..
value | "AQAAADIBAABiAGMLAAcAAABsb25nQ29sAGZsb2F0Q29sA..
partition| 0 ..
offset | 0 ..
When a consumer is no longer required, it’s good practice to delete the instance and free up resources on the REST proxy. The REST API enables clients to perform that operation by using a DELETE request.
q)// delete the consumer instance once no longer required
q)req[baseURI;`DELETE;header;""]
""Confirmation that the instance was deleted can be got by running the same command as earlier:
$ /bin/kafka-consumer-groups --bootstrap-server localhost:9092 --describe -group myConsumerGroup
Consumer group 'myConsumerGroup' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
myConsumerGroup data 0 1 1 0 - - -Producing and consuming from multiple partitions
In the first example, the entire table was embedded under the value object and published to a topic with a single partition. More often than not, it makes sense to split a topic into a number of partitions, as this allows for higher throughput by means of parallelism. Also, in certain cases, it might make sense to publish messages with some key identifier. If using the DefaultPartitioner, messages with the same key will get routed to the same partition. The default Kafka partitioner uses a hash algorithm to hash the key of each message and then modulo the number of partitions to map each key to a partition number. Kafka guarantees order within a partition. However, if further partitions are added at a later stage, order is no longer guaranteed. It should be noted that Kafka does not support decreasing the partition number.
To illustrate how this can be done using the Kafka REST proxy, first we will manually create a topic with three partitions using the command line:
$ /bin/kafka-topics --bootstrap-server localhost:9092 --create --topic 3partTopic --partitions 3 --replication-factor 1
$ /bin/kafka-topics --bootstrap-server localhost:9092 --describe -topic 3partTopic
Topic:3partTopic PartitionCount:3 ReplicationFactor:1 Configs:segment.bytes=1073741824
Topic: 3partTopic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: 3partTopic Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: 3partTopic Partition: 2 Leader: 0 Replicas: 0 Isr: 0The producer code is similar to before, except the payload will now include a key object. The payload will batch together multiple messages into a single HTTP request. The values in the column symCol will be used as the key for each message. The data will be serialized to IPC bytes like in the previous example. The message distribution amongst the partitions will be extracted from the HTTP response and displayed to the console.
producer.q
k)req:{[url;method;hd;bd]d:s,s:"\r\n";url:$[10=@url;url;1_$url];p:{$[#y;y;x]}/getenv`$_:\("HTTP";"NO"),\:"_PROXY";u:.Q.hap@url;t:~(~#*p)||/(*":"\:u 2)like/:{(("."=*x)#"*"),x}'","\:p 1;a:$[t;p:.Q.hap@*p;u]1;(4+*r ss d)_r:(`$":",,/($[t;p;u]0 2))($method)," ",$[t;url;u 3]," HTTP/1.1",s,(s/:("Connection: close";"Host: ",u 2),((0<#a)#,$[t;"Proxy-";""],"Authorization: Basic ",.Q.btoa a),($[#hd;(!hd),'": ",/:. hd;()])),($[#bd;(s,"Content-length: ",$#bd),d,bd;d])}
data:update symCol:10#`red`purple`yellow from flip`longCol`floatCol`dateCol`timeCol`stringCol`boolCol!10?/:(10;10f;.z.D;.z.T;0N 3#.Q.a;0b);
buildKeyValueObjects:{"{\"key\":\"",(.Q.btoa string y x),"\",\"value\":\"",(.Q.btoa`char$-18!y),"\"}"};
buildPayload:{"{\"records\":[",(","sv x),"]}"};
topicURL:"http://localhost:8082/topics/3partTopic";
producerHeaders:("Content-Type";"Accept")!("application/vnd.kafka.binary.v2+json";"application/vnd.kafka.v2+json");
// embed each message in a single HTTP payload
response:req[topicURL;`POST;producerHeaders;]buildPayload buildKeyValueObjects[`symCol;]each data;
// display partition distribution of each key (symCol value)
show `partition xgroup distinct(select partition from .j.k[response]`offsets),'select symCol from data;
exit 0The consumer code has changed slightly. The script below takes a unique consumer instance name as its sole parameter. The consume GET request is wrapped in a function named poll, which extracts any data and displays to the console. The poll function is then called within .z.ts which will be invoked every 5 seconds.
consumer.q
k)req:{[url;method;hd;bd]d:s,s:"\r\n";url:$[10=@url;url;1_$url];p:{$[#y;y;x]}/getenv`$_:\("HTTP";"NO"),\:"_PROXY";u:.Q.hap@url;t:~(~#*p)||/(*":"\:u 2)like/:{(("."=*x)#"*"),x}'","\:p 1;a:$[t;p:.Q.hap@*p;u]1;(4+*r ss d)_r:(`$":",,/($[t;p;u]0 2))($method)," ",$[t;url;u 3]," HTTP/1.1",s,(s/:("Connection: close";"Host: ",u 2),((0<#a)#,$[t;"Proxy-";""],"Authorization: Basic ",.Q.btoa a),($[#hd;(!hd),'": ",/:. hd;()])),($[#bd;(s,"Content-length: ",$#bd),d,bd;d])};
base64decode:{c:sum x="=";neg[c]_"c"$raze 1_'256 vs'64 sv'69,'0N 4#.Q.b6?x};
instName:`$.z.x 0;
consumerGroupURL:"http://localhost:8082/consumers/myNewGroup";
header:enlist["Content-Type"]!enlist"application/vnd.kafka.v2+json";
consumerHeaders:enlist["Accept"]!enlist"application/vnd.kafka.binary.v2+json";
// create consumer instance in a consumer group named 'myNewGroup'
baseURI:last .j.k req[consumerGroupURL;`POST;header;.j.j(`name`format`auto.offset.reset)!(instName,`binary`earliest)];
// consumer instance subscribe to the topic '3partTopic'
req[baseURI,"/subscription";`POST;header;"{\"topics\":[\"3partTopic\"]}"];
// function which sends a GET request to records resource and displays any data
poll:{r:.j.k req[baseURI,"/records";`GET;consumerHeaders;""];$[count r;show(-9!`byte$ base64decode@)each r`value;-1"No new data"];}
.z.ts:poll;
\t 5000As the topic has three partitions, it makes sense to have a single consumer group with three consumer instances. When all three instances are up and running, each will be assigned a different partition. As shown in the following illustrations the first few invocations of the poll function return no data as expected, until the producer script is executed. The next few polls also return no data. The producer code is executed one final time to illustrate how Kafka will continue to route messages with the same key to the same partitions.
CONSUMER 1
$ q consumer.q consumer1 -q No new data No new data longCol floatCol dateCol timeCol stringCol boolCol symCol ----------------------------------------------------------------- 8 2.296615 2007.12.08 07:57:14.764 "vwx" 0 red 5 6.346716 2017.05.31 01:47:51.333 "stu" 1 red 6 9.49975 2013.08.26 14:35:31.860 "jkl" 0 red 5 5.919004 2011.07.06 14:52:17.869 "yz" 0 red No new data No new data longCol floatCol dateCol timeCol stringCol boolCol symCol ----------------------------------------------------------------- 8 2.296615 2007.12.08 07:57:14.764 "vwx" 0 red 5 6.346716 2017.05.31 01:47:51.333 "stu" 1 red 6 9.49975 2013.08.26 14:35:31.860 "jkl" 0 red 5 5.919004 2011.07.06 14:52:17.869 "yz" 0 red No new data No new data
CONSUMER 2
$ q consumer.q consumer2 -q
No new data
No new data
longCol floatCol dateCol timeCol stringCol boolCol symCol
-----------------------------------------------------------------
9 4.707883 2006.06.02 04:25:17.604 "pqr" 0 yellow
6 2.306385 2013.01.05 02:59:16.636 "def" 1 yellow
8 5.759051 2018.07.24 08:31:52.958 "vwx" 0 yellow
No new data
No new data
longCol floatCol dateCol timeCol stringCol boolCol symCol
-----------------------------------------------------------------
9 4.707883 2006.06.02 04:25:17.604 "pqr" 0 yellow
6 2.306385 2013.01.05 02:59:16.636 "def" 1 yellow
8 5.759051 2018.07.24 08:31:52.958 "vwx" 0 yellow
No new data
No new dataCONSUMER 3
$ q consumer.q consumer3 -q
No new data
No new data
longCol floatCol dateCol timeCol stringCol boolCol symCol
-----------------------------------------------------------------
1 6.919531 2009.01.26 02:31:39.330 "yz" 1 purple
4 9.672398 2006.09.28 15:50:12.140 "mno" 1 purple
1 4.39081 2012.04.30 14:01:18.498 "jkl" 0 purple
No new data
No new data
longCol floatCol dateCol timeCol stringCol boolCol symCol
-----------------------------------------------------------------
1 6.919531 2009.01.26 02:31:39.330 "yz" 1 purple
4 9.672398 2006.09.28 15:50:12.140 "mno" 1 purple
1 4.39081 2012.04.30 14:01:18.498 "jkl" 0 purple
No new dataConsumer1 consumed messages with the key red. Consumer2 consumed messages with the key yellow. Finally, consumer3 consumed messages with the key purple. This behavior corresponds with the distribution of the messages across the three partitions which can be seen from the output of the producer.
$ q producer.q -q
partition| symCol
---------| ------
0 | red
2 | purple
1 | yellow
$
$ q producer.q -q
partition| symCol
---------| ------
0 | red
2 | purple
1 | yellowThe partition assignments of each consumer and their offsets can be viewed by running the following command.
$ /usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --describe -group myNewGroup
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
myNewGroup 3partTopic 1 6 6 0 consumer-3-979a9701-fa65-40d1-a87a-3962ad7fac95 /172.31.13.158 consumer-3
myNewGroup 3partTopic 0 8 8 0 consumer-2-92c29f4c-58de-464a-80e1-24299bfab8cd /172.31.13.158 consumer-2
myNewGroup 3partTopic 2 6 6 0 consumer-4-92ef22e4-ac9a-4da7-9ee0-c208afbe8247 /172.31.13.158 consumer-4Summary
In this blog post, you learned what Kafka is at a very basic level, what a simple Kafka pub-sub system looks like and what REST is along with its placement within the Kafka ecosystem. We successfully produced data to Kafka and consumed it on the opposite end while maintaining data consistency. You should now be aware of how HTTP requests are constructed and executed from within kdb+. You saw how to overwrite consumer offsets by sending a quick HTTP request. Finally, we displayed how Kafka achieves scale by means of parallelism across numerous partitions.
There are tradeoffs and limitations to the Kafka REST proxy. It’s yet another process within the cluster which needs to be managed and multiple proxy instances may be required depending on load. There is a performance cost in the construction of HTTP requests on the kdb+ clients and furthermore, HTTP connections are not persistent, so HTTP requests are not overly efficient. These requests require further translation into native Kafka calls on the REST proxy itself. For produce and consume requests, there will be an overhead of transforming embedded data between formats.
Therefore for high throughput, it may be better to use the kfk library but we hope this blog post has proved helpful in displaying the functionality and flexibility of kdb+.
Sources
https://docs.confluent.io/current/kafka-rest/quickstart.html
https://docs.confluent.io/current/kafka-rest/api.html#api-v2
https://github.com/jfealy/kafka-rest



