By Conor McCarthy
Following the KX machine learning team’s release last year of JupyterQ, a Jupyter kernel for kdb+, there has been increased interest in the use of Jupyter notebooks for code development within the kdb+/q community. In this article we take a look at Jupytext by developer Marc Wouts, which attempts to solve one of the most frustrating aspects of using Jupyter notebooks within a team environment, namely version control.
The inherent difficulty with version control in regard to Jupyter notebooks surrounds the output format of Jupyter notebooks. For example, compare notebooks that render like this with the associated JSON code that they contain. Here is the rendering:
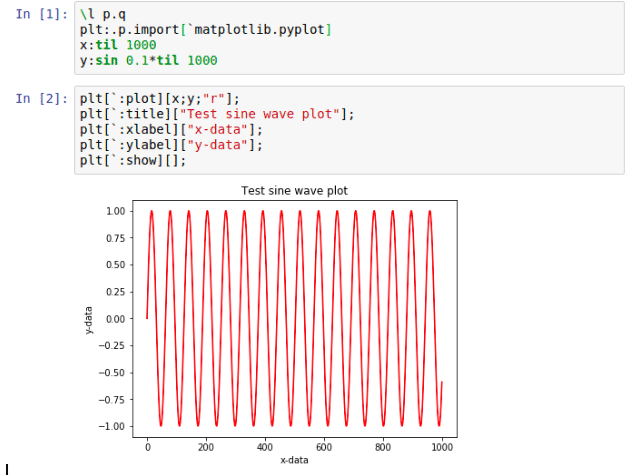
The associated JSON code, for various aspects of the notebooks, are extremely verbose, as seen in the following, which has been trimmed for clarity:

While the renderings produced are aesthetically pleasing, the code itself can make auto-merging troublesome and the Github diffs unmanageable. As a result the important changes to the code base can be lost within unimportant formatting.
As outlined on code.kx.com here it is possible to use the in-built download capabilities of Jupyter to allow for the code contained within the cells of notebook to be saved to a .q file.
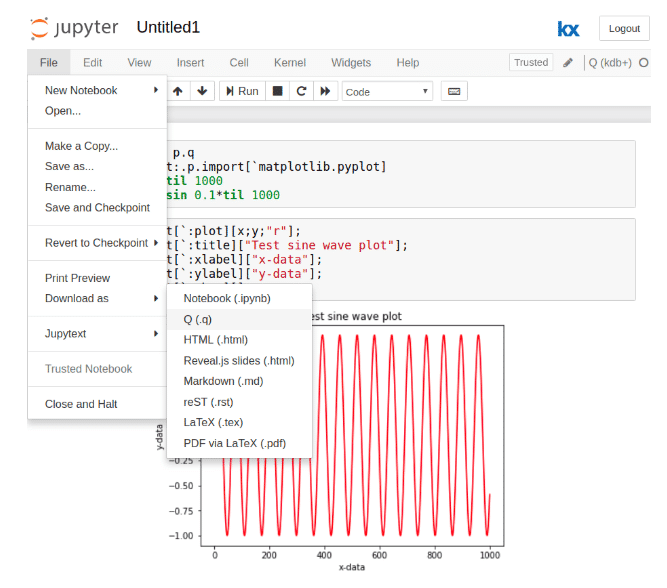
However, this does not maintain any information regarding code comments or section titles which are commonly written in markdown script within a data science workflow using Jupyter notebooks. In conjunction with this, downloads must be completed manually with no paired auto-update.
Jupytext
Developed by Marc Wouts and available for free under the MIT license, Jupytext aims to solve all of the issues mentioned above. As outlined on Github, Jupytext is available both through pypi and on conda-forge via:

Once installed, an extension for Jupyter Notebooks will be added to the file menu as seen below, this extension allows the notebook to be paired with a script formatted as per the desired language:
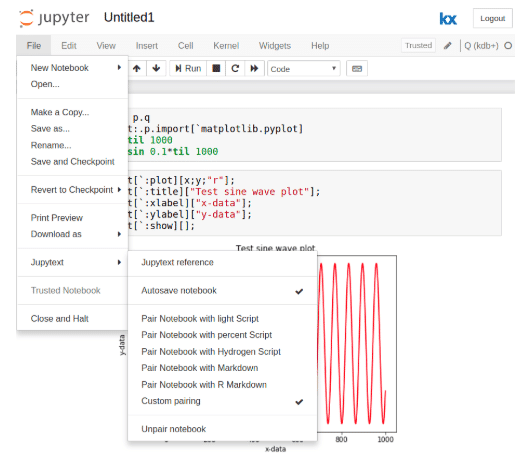
Jupytext natively supports the saving of kdb+/q scripts through pairing with light script. This results in the creation of a paired q-script. The output q-script contains the following commented header which defines the kernel being used and the language formats of the notebooks:

An example of the converted output between the two formats to show the improved clarity of output is as follows:
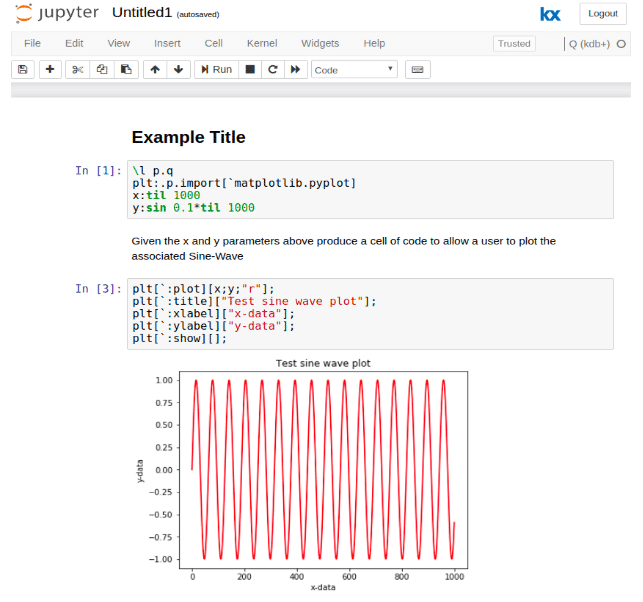
With an equivalent q script:

Clearly this new format has removed the verbose data associated with images and is in a format which is much easier to work with than the .ipynb JSON file, thus providing meaningful version control diffs. At the same time it also retains important markdown cells which are lost in the raw q-script download.
It should be noted here that in the case when an individual has Jupytext installed, opening the q-script above within the Jupyter notebook main page will generate an associated ![]() file. This has the benefit of meaning that the notebook file does not need to be kept under version control.
file. This has the benefit of meaning that the notebook file does not need to be kept under version control.
This q-script is fully executable via a command line similar to any conventional q-script. Modifications to the q-script result in immediate changes to the notebook file on save and vice-versa. This allows users who prefer to work in vim to edit files in parallel with those using notebooks. This type of flexibility is particularly important in large organizations.
Full documentation for this tool is available here. For further information on JupyterQ visit the KX Developers’ site here. If you have any further questions on JupyterQ, or any of the machine learning tools provided by KX, please don’t hesitate to contact us at ai@devweb.kx.com.



