By Gopala Bhat
A useful feature in kdb+ version 3.6 is the ability to defer the response to synchronous IPC messages. The value of this becomes more apparent when systems grow and have to handle many users. This short blog post demonstrates a simple use case with a few lines of code.
Deferred Response can be considered a more efficient method to serve data to client processes. It bypasses the traditional bottleneck that occurs when the serving process must wait for all functions to respond with a result in sequence. The explanation of this feature is put in the context of a client-gateway-worker process set up.
To introduce this topic it is necessary to revisit the fundamentals of IPC; they are the synchronous and asynchronous message handling functions .z.pg/.z.ps built into the q language.
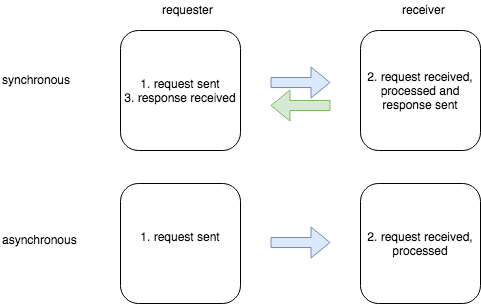
In the picture above, synchronous messaging is where a requesting process passes a message to a receiving process, waits until the message has been received and processed and then the result sent back. Simply put, the .z.pg function takes the inbound query, processes and returns the result of the query.
Furthermore, an asynchronous message sent from a requester will not receive a response. Processing will occur on the receiver but the requester is free to proceed with other tasks. In this case, the .z.ps function will process the inbound query but return nothing. Both message response functions are explained in greater detail at https://code.kx.com/wiki/Cookbook/IPCInANutshell.
Consider a simple client-gateway-worker architecture as pictured below. Each process communicates using synchronous messaging to serve data to the client. For simplicity, we use a set of stored procedures defined on all processes: a client, a gateway, a real-time database (RDB) and an historical database (HDB).
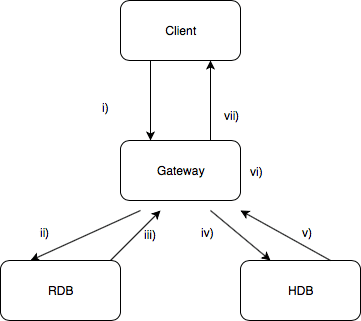
Simple client-gateway-worker
i) The client calls a stored procedure synchronously on the gateway. The gateway executes which ii) synchronously calls and iii) receives a response from the RDB. It stores the result and continues to iv) synchronously request and v) receive from the HDB. This result is also stored and vi) aggregated with the results from the RDB before being returned vii) to the client.
The beauty of this framework is its simplicity, function calls flow in sequence with minimal code needed. However, using synchronous messaging exclusively imposes delays. The gateway process must wait for the stored procedure to finish on the RDB before it can execute the next instruction on the HDB. As an application scales, with more client processes requesting data, the gateway process becomes the bottleneck when waiting to accept new queries and return the results from old queries.
//sample code on client
hsim:hopen `::5000;
res0:hsim("proc0";`IBM;10);
//sample code on gateway
hrdb:hopen `::5001;
hhdb:hopen `::5002;
/return all trades for stock s in the last h hours
/sample usage: proc0[`IBM;10]
proc0:{[s;h]
st:.z.P;
res_rdb:hrdb("proc0";s;h);
res_hdb:hhdb("proc0";s;h);
res:res_rdb upsert res_hdb;
(res;.z.P-st)
};
//sample code on RDB
/return all trades for stock s in the last h hours, need a date column to match with HDB result
proc0:{[s;h]
st:.z.P-`long$h*60*60*(10 xexp 9);
res:`date xcols update date:.z.D from select from trade where sym=s,time>=st;
res
}
//sample code on HDB
/return all trades for stock s in the last h hours
proc0:{[s;h]
st:.z.P-`long$h*60*60*(10 xexp 9);
res:select from trade where date>=`date$st,sym=s,time>=st;
res
}What if the gateway could be relieved of its waiting duties? What if the gateway could execute those stored procedures on the RDB and HDB but not have to wait for the former before executing the latter?
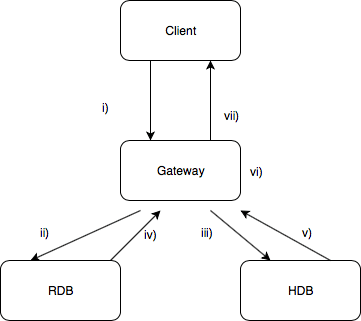
Deferred Response client-gateway-worker
The client makes i) a synchronous request of the stored procedure to the gateway. The gateway asynchronously dispatches the work to the ii) RDB and the iii) HDB without waiting for a response. The iv) RDB and v) HDB respond in kind asynchronously. Lastly the gateway vi) aggregates before vii) sending back a response to the client.
What does Deferred Response mean?
In the figure above, the gateway dispatches orders to the RDB/HDB without waiting for a response.
This is the “deferred” part of deferred response, meaning that the gateway executes a query but does not return a result immediately, rather it pushes the result to later when it has time. The default behavior of the synchronous messaging function .z.pg is to explicitly return the result as soon as the code has been executed; this corresponds with the simple gateway setup.
By modifying .z.pg to include the internal function -30!, .z.pg will not return a result at the end of executing the code.. -30! is added to .z.pg in two steps:
-30!(::) //terminates the function without returning a value
-30!(handle;isError;msg) //used to publish the message at given opportunityi) Deferring the response
//Default Definition
.z.pg:{[query]value query} //argument x has been replaced with query for clarity
//Deferred Response Definition
.z.pg:{[query]
st:.z.P;
sp:query[0];
remoteFunction:{[clntHandle;query;st;sp]
neg[.z.w](`callback;clntHandle;@[(0b;)value@;query;{[errorString](1b;errorString)}];st;sp)
};
neg[workerHandles]@\:(remoteFunction;.z.w;query;st;sp); / send the query to each worker
-30!(::); / defer sending a response message - return value of .z.pg is ignored
}The default behavior of .z.pg is to return the result of the query. In the simple set-up, the stored procedure is defined outside of .z.pg and is executed as part of the argument which is passed to the function. By contrast, in the Deferred Response example, .z.pg has been significantly modified. .z.pg defines remoteFunction, which will execute on each worker and in-turn call the respective stored procedure. Each remoteFunction call is passed asynchronously before the message handler terminates with -30!(::). i.e the response has been deferred. Notice that remoteFunction now serves as a proxy for the default .z.pg definition by calling value on the stored procedure (query). Additionally, the stored procedures are no longer required to be defined on the gateway. Once remoteFunction finishes, the result is returned to the function callback via the preserved handle stored in .z.w. Fundamentally this is an implementation of asynchronous callbacks which are discussed in further detail https://code.kx.com/wiki/Cookbook/Callbacks.
ii) Returning the result
Adding -30!(::) stopped .z.pg from returning and the gateway became free to receive further synchronous queries. However, once the RDB/HDB worker processes have results to publish, they must call back to the gateway as per the definition of .z.pg.
The function callback, defined on the gateway, collects results, aggregates them and returns them to the client; in essence generalizing the work originally carried out by the stored procedures defined on the gateway.
Once the results are returned and aggregated, the second part of -30!, -30!(handle;isError;msg), is called to return the result. Error handling is built into the response mechanism and if either worker throws an error, this will be propagated to the client. In addition, the handle argument must be defined in .z.W and will be waiting for a response – otherwise an error will be thrown.
callback:{[clientHandle;result;st;sp]
pending[clientHandle],:enlist result;
if[count[workerHandles]=count pending clientHandle;
isError:0<sum pending[clientHandle][;0];
result:pending[clientHandle][;1];
reduceFunction:reduceFunctionDict[sp];
r:$[isError;{first x where 10h=type each x};reduceFunction]result;
-30!(clientHandle;isError;(r;.z.P-st));
pending[clientHandle]:()
]
}Once all of the results are returned from the workers for a given client handle, the message is explicitly sent via -30!(handle;isError;msg). Note that until the client handle receives a response via -30! it will not unblock. This can be tested by trying to asynchronously flush the handle from the gateway side using neg[h]””. The response portion is embedded at the end of the callback function, however, it is possible to place it inside any function and call with the appropriate arguments at will. A trivial example would be to have it always return 1.
//gateway
callback:{[clientHandle;result;st] pending[clientHandle],:enlist result}
pending:()!()
flushRes:{[clientHandle]-30!(clientHandle;0b;1)}
//client
h(“proc1”;`IBM)
//gateway
pending
8| 0b +`sym`MAX!(,`IBM;,99.99993) 0b +`sym`MAX!(,`IBM;,99.99996)
flushRes[8i]
//client
1In the Deferred Response architecture, we are not shifting the processing of data away from the gateway, merely changing how the gateway requests, receives and aggregates before returning the result. Note also that this example only uses a simple query where the order of results are not relevant.
In conclusion, including -30! unlocks the Deferred Response feature. The synchronous message function and a callback function combined ensure that the gateway is no longer the bottleneck receiving and publishing requests. Should the number of client processes increase, those too will be handed off to the workers asynchronously, enabling the application to scale.



