The KX Proof of Concept (POC) team is based in Newry and offers assistance to clients who want to better understand how KX can operate in their domain and sometimes on their data. It provides an opportunity to explore the many diverse use cases to which KX technology can be applied. In this series of blogs we discuss some of the projects we have recently undertaken.
by Paul Scott
As the volume of data being produced grows exponentially, particularly from remote sources, developers have been searching for alternative and more efficient methods of capturing and unlocking the value it contains. A recent approach has been that of Edge Computing. This approach harnesses the power of low-profile devices to process and part-analyze the data locally before remitting to a central server, in contrast to the standard approach where all processing is centralized. Clearly, in instances where there are many remote sources publishing data at high frequencies, the Edge approach has the potential to vastly improve performance through local processing and reducing the amount of data being transmitted back to a central server. This blog and the accompanying video outlines a POC that the team was asked to undertake for a cyber security client who wanted to explore how KX could be installed on a low-end device (in this case choosing a Raspberry Pi as an extreme example), to illustrate the concept of edge processing.
The use case selected was to monitor a low-profile device for “virus” processes that we had simulated on it. Our aim was to demonstrate the ability of kdb+ to work with low-profile devices as an example of its “green programming” pedigree in data processing discussed previously in this blog. We also wanted to illustrate how, through the use of embedPy, we could invoke Python libraries on the server side for processing the data to find these simulated viruses. An additional requirement was to demonstrate the resilience of this system by showing that we can completely disconnect the edge device from our server yet maintain no loss of data when doing so. For that reason the POC also demonstrate the ability to run the KX Platform, which provides such supporting run-time services, on a low-profile device (https://devweb.kx.com/solutions/the-enterprise/).
Below is a diagram of our configuration. On the left-hand side, we have our edge device (a Raspberry PI 3 running a modified daemon installation of the Enterprise Platform) for chained data ingestion). On the right hand side we have our central server which is running a standard KX installation.
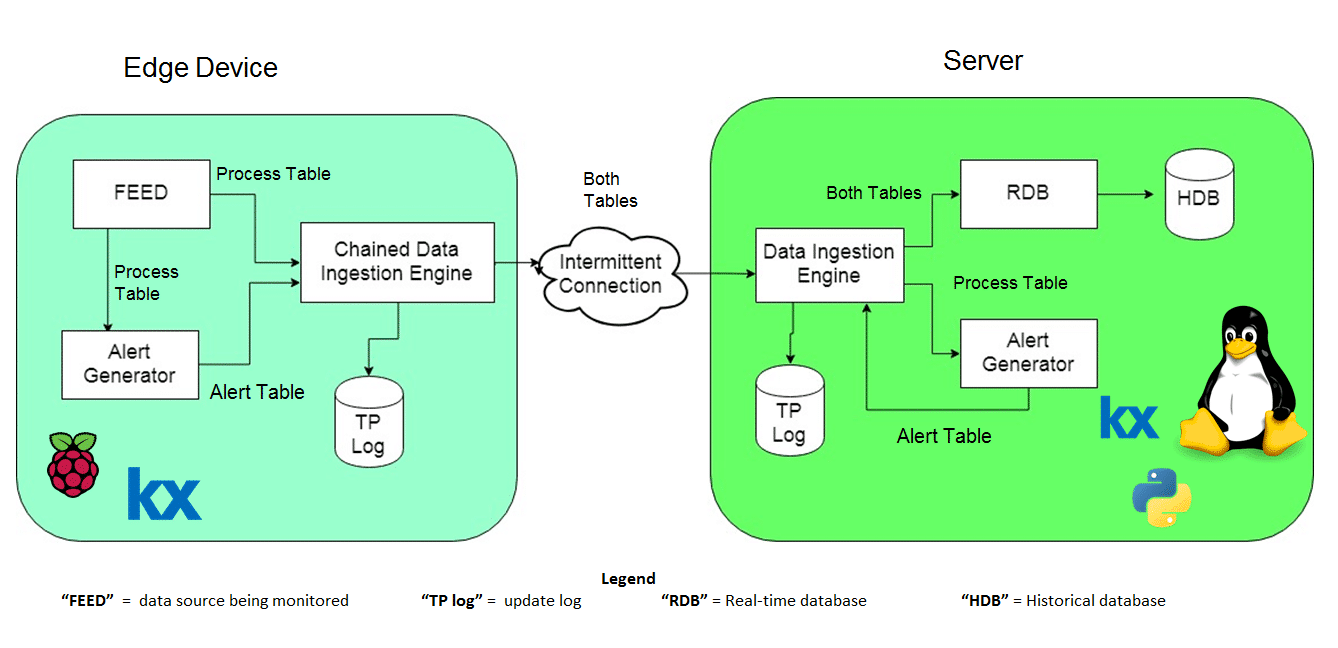
Data flows through the system as follows:
Starting from the Edge device, we have our FEED. The FEED is running the system command “ps –aux” to gather information about all the processes running. It is here we insert our simulated viruses. In order to do so we simply select a random number of rows and change attributes like the process name, CPU usage and Memory Usage on these rows.
From here we pass this data in the form of a kdb+ table to our Alert Generator. It is at this point that we capture our viruses. We create a new table, Alert Table, storing information about these “virus” processes and pass it to our chained data ingestion engine.
The chained data ingestion engine receives two tables, the process table and the alert table. The data ingestion engine will hold the most recent messages in memory as well as logging all of the incoming updates to disk.
What allows us to maintain no loss of data is the fact that the chained data ingestion engine will push the first messages received to the server before the latest updates, so that if the connection drops just before the chained data ingestion engine receives an update, and then once the connection comes back another update is received. The message received just after the connection drop will be sent first.
From here, if the chained data ingestion engine is connected to the server these tables are simply pushed to the data ingestion engine located on the server. Effectively acting as the FEED for the server’s data ingestion engine, however if there is no connection the data will be held on our edge device until the connection is restored.
On the server side, as stated previously, we are running the standard KX platform. The most interesting feature here is the addition of machine learning in the server alert generator. With the use of embedPy we are able to import the scikit learn library into our kdb+ scripts and create a model using LASSO regression. This model uses the CPU usage, memory usage, virtual size and resident set size of the processes to decide whether a process should be classified as a virus or not. (If you wish to learn more about using embedPy to perform LASSO regression I recommend this recent whitepaper by Samantha Gallagher)
To summarize, we successfully installed our Enterprise Platform onto a low-profile device and have created a process flow in which data can be processed locally on our device before being transferred over an intermittent connection to our central server. The key factors in enabling us to do this have been the small footprint of kdb+, the simplicity of its architecture, the ease of connecting to other technologies like Python to reuse existing machine learning functionality, and the support of the KX platform for managing failover conditions.
Please click on this link to view a video of the POC set-up and more detail on how it operates



