By Conor McCarthy
The KX machine learning team has an ongoing project of periodically releasing useful machine learning libraries and notebooks for kdb+. These libraries and notebooks act as a foundation to our users, allowing them to use the ideas presented and the code provided to access the exciting world of machine learning with KX.
This release, which is the second in a series of releases in 2019, relates to the areas of cross-validation and standardized code distribution procedures for incorporating both Python and q distribution. Such procedures are used in feature creation through the FRESH algorithm and cross-validation within kdb+/q.
The toolkit is available in its entirety on the KX GitHub with supporting documentation on the Machine Learning Toolkit page of the KX Developers’ site.
As with all the libraries released from the KX machine learning team, the machine learning Toolkit (ML-Toolkit) and its constituent sections are available as open source, Apache 2 software.
Background
The primary purpose of this library is to provide kdb+/q users with access to commonly-used machine learning functions for preprocessing data, extracting features and scoring results.
This latest release expands on the scoring and feature extraction aspects of the toolkit, by introducing two new areas of functionality and improving functions contained in the machine learning toolkit:
- Cross-validation and grid search functions to test the ability of a model to generalize to new or increased volumes of data.
- A framework for transparently distributing jobs to worker processes, including serialized Python algorithms.
- .ml.df2tab and .ml.tab2df now support time and date types for conversion which improves function performance as incompatible types are no longer returned as foreigns.
Technical description
Cross-Validation
Cross-validation is used to gain a statistical understanding of how well a machine learning model generalizes to independent datasets. This is important in limiting overfitting and selection bias, especially when dealing with small datasets. A variety of methods exist for cross-validation, with the following implemented in this release:
- Stratified K-Fold Cross-Validation
- Shuffled K-Fold Cross-Validation
- Sequentially Split K-Fold Cross-Validation
- Roll-Forward Time-Series Cross-Validation
- Chain-Forward Time-Series Cross-Validation
- Monte-Carlo Cross-Validation
All of the aforementioned methods have been implemented in kdb+/q and are documented fully on code.kx.com here. For each of these methods, a grid search procedure has also been implemented allowing users to find the best set of hyperparameters to use with a specific machine learning algorithm.
The roll-forward and chain-forward methods have particular relevance to time-series data. These methods maintain a strict order where the training sets precede the validation sets, ensuring that future observations are not used in constructing a forecast model. A graphical representation of each is provided below.
Roll-forward cross-validation
This method tests the validity of a model over time with equisized training and testing sets, while enforcing that the model only test on future data.

Image 1. Roll-forward validation
Chain-forward cross-validation
This method tests the ability of a model to generalize when retrained on increasingly larger volumes of data. It provides insight into how the accuracy of predictions is affected when expanding volumes of training data are used.

Image 2. Chain-forward validation
Full documentation on the cross-validation functions can be found here.
Standardized multiprocess distribution framework
A framework has been developed to transparently distribute jobs to worker processes in kdb+/q. This framework supports distribution of both Python and q code, this has been incorporated into the FRESH and cross-validation libraries and is also available as a standalone library. Distribution works as follows:
- Initialize a q process with four workers on a user-defined central port.
$ q ml/ml.q -s -4 -p 1234- Load the library ( .ml.loadfile`:util/mproc.q) into the main process.
- Call .ml.mproc.init to create and initialize worker processes, e.g. to initialize workers with the FRESH library, call
.ml.mproc.init[abs system"s"]enlist".ml.loadfile`:fresh/init.q"Which results in the following architecture
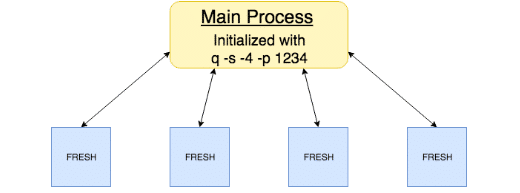
Within the toolkit, work involving both the FRESH and cross-validation procedures will be automatically peached if the console has been started with a defined number of worker processes and main port. The procedures can be initialized by running either of the following:
FRESH process
q)\l ml/ml.q // initialize ml.q on the console
q).ml.loadfile`:fresh/init.q // initialize freshCross-Validation process
q)\l ml/ml.q // initialize ml.q on the console
q).ml.loadfile`:xval/init.q // initialize cross-validationWhile general purpose in nature, this framework is particularly important when distributing Python.
The primary difficulty with Python distribution surrounds Python’s use of a Global Interpreter Lock (GIL). This limits the execution of Python bytecode to one thread at a time, thus making distributing Python more complex than its q counterpart. We can subvert this by either wrapping the Python functionality within a q lambda or by converting the Python functionality to a byte stream using Python ‘pickle’ and passing these to the worker processes for execution. Both of these options are possible within the framework outlined here.
If you would like to further investigate the uses of the machine learning toolkit, check out the machine learning toolkit on the KX GitHub to find the complete list of the functions that are available in the toolkit. You can also use Anaconda to integrate into your Python installation to set up your machine learning environment, or you build your own which consists of downloading kdb+, embedPy and JupyterQ. You can find the installation steps here.
Please do not hesitate to contact ai@devweb.kx.com if you have any suggestions or queries.



