



Charles Dickens couldn’t have known much about databases, but when he said “It was the best of times, it was the worst of times”, he described perfectly some of their attempts to accommodate temporal data. It’s a sentiment echoed by Daryl Plummer, Distinguished Analyst and Gartner Fellow, at the recent Gartner Data and Analytics Summit in Florida. In his keynote address on “The New Economics of Technology and Data”, he describes the digital age as the coming together of the physical and virtual worlds to enable the creation of new value and outcomes. But, he cautions, it only works if they are combined correctly and he emphasises that they seldom are, particularly in relation to time series data.
Part of the problem, he explains, is an assumption that because features like timestamps and temporal columns may be supported, so too is the full power of time series analytics. But that ignores the specialised functionality required to perform, say, aggregations and regressions efficiently over long time periods or to correlate information quickly and easily across disparate data sets in order to identify trends and predict outcomes. For that reason, he counsels strongly against the crude but prevalent approach of “force fitting temporal data into a conventional data store.” His advice: “Stop doing that.”
Plummer’s recommended approach is the coupling of a time series database, one specifically designed and optimised for the characteristics of time series data, with a processing capability that acts directly upon that data. Conceptually, it’s – a processing environment where data and the query language acting upon it are one so that data translation is minimised for maximum efficiency. kdb Insights Enterprise is a proven example, combining the high-performance time series database kdb with q, its integrated vector-based programming language. Now, kdb Insights on Amazon FinSpace makes it even more powerful, harnessing the scale and resources of AWS to make those proven on-premises capabilities of kdb easily and instantly available in the cloud as a managed service.
kdb Insights on FinSpace runs natively on AWS to access all the benefits of its cloud-based technologies and services for delivering vector-based time series data analytics. Those capabilities include low-cost storage in S3 tiers, compute elasticity over EC2, streaming via Kinesis and serverless deployment on Lambda at an infrastructural level. They extend to its expansive catalogue of microservices that enable rapid, agile development and deployment of new applications using Docker and Kubernetes. Supporting them all are 24/7 operations and Multi-Availability Zones for support, resilience and security monitoring.
Easy to Adopt
Users wishing to build enterprise applications on kdb can connect to Amazon FinSpace and configure a complete kdb processing and analytics environment with just a few clicks. From there they can quickly develop business-critical use cases ranging from options pricing simulations to transaction cost analysis driven by data science and machine learning based on real-time and historical data.
For those who have already built their enterprise applications on-premises using kdb, migrating to the cloud is even easier. Assisted by a set of migration tools, it is simply a matter of running the same q code and scripts to have instant access to the same functionality on kdb Insights core, the cloud version of kdb, upon which kdb Insights Enterprise is based. No code refactoring or revisions to existing interfaces to on-prem data is required. Moreover, it can be done on existing licences.
In both cases, developers and data engineers can focus on data analytics and more agile solution development, by having delegated infrastructure support and maintenance to a managed service that ensures system stability and autoscaling (up and down) to meet their processing needs.
Simple to Extend
Once operational, users then have access to the full range of Amazon FinSpace microservices including a set of kdb-based microservices for supporting the data management and analytics lifecycle, from capture and storage through to visualisation and distribution. The microservices and supporting architecture enable customers to selectively replace their existing functionality or adopt new capabilities with microservices developed and supported by KX. As a result, internal resources can concentrate on business-focussed development that deliver competitive edge rather than generic data management needs.
Fast to Market
Some organisations may wish to minimise their in-house development even further and use the KX-provided UI for defining and deploying data pipelines for capturing, transforming and visualising data. Within this approach there still remains the capability to perform client-specific functionality. Customers can create enterprise-wide User Defined Functions that extend the out-of-the-box microservices, or at the “pro-code” level, they can insert bespoke Python or SQL code directly into their data pipelines.
A Client Use Case: From Voice to Value:
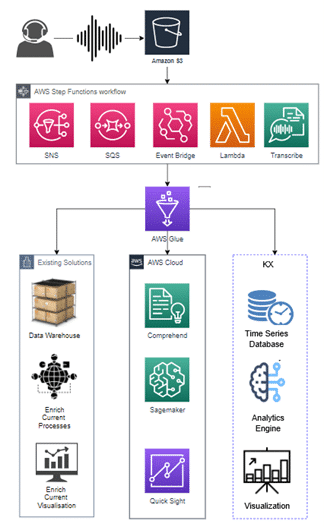
kdb Insights on Amazon FinSpace brings effectively unlimited resources and scalability to developers, enabling them to concentrate on developing core business functionality rather than dealing with infrastructure issues. Those benefits and the flexibility of those combined services was exemplified in a regulatory use case where the compliance department extracted previously untapped value from a set of voice recordings held until then only for regulatory reasons. In this case, the bank’s compliance department used a combination of standard and audio-specific services to build their application, illustrating the flexibility of the development environment.
On the infrastructure side, AWS Lambda was selected as a serverless run-time environment to save on costs and provide elasticity as needed, S3 for storage, AWS Kinesis for messaging and AWS Glue for ETL. This provided a quick environment for the ingestion and processing of data as well as supporting cloud services for authentication, logging, and monitoring. On the audio-specific side, voice-focussed microservices like Transcribe for converting voice to text-enabled developers to quickly derive metrics like talk-time ratios, silence intervals and interruption rates. More advanced work using Comprehend for NLP and SageMaker for machine learning enabled further insights in areas like sentiment analysis and determining compliance with disclosure obligations.
Time for Disruption
In his keynote speech mentioned above, Daryl Plummer presented an interesting slide highlighting the message that if you miss the signals of technology disruption you may never recover. The full-scale adoption of a Timehouse combining a vector-based time-series database and analytics engine in one for extracting critical and actionable insights is one such disruption in the coupling of physical and virtual worlds. Some may say it’s achievable within existing configurations and continue forcing temporal data where it doesn’t fit, whereas the more enlightened will adopt new solutions like kdb Insights Amazon FinSpace. Dickens seems to have foreseen that too – “It was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity”. For those who ignored the disruption and stuck with the old ways. But for those who didn’t and embraced the new their expectations can only be, well, great.


