



Hybrid data: The key to unlocking generative AI accuracy
New research shows that using semantically structured data with generative AI makes answers three times more accurate than a Large Language Model (LLM) with SQL. Unfortunately, traditional databases and LLMs aren’t designed to work together, and building a bridge over that divide is hard.
Vector databases have emerged to fill that gap. But bolt-on vector search isn’t enough to improve query accuracy, simplify prompt engineering, or make building GenAI applications more cost-effective. A better solution is a hybrid approach that uses data as guide rails for accuracy.
Here’s a fresh look at how hybrid data computing helps deliver more accurate GenAI applications.
What is hybrid data, and why does it matter?
Hybrid computing is a style of building applications that fuses unstructured and structured data to capture, organize, and process data. Sounds simple, right?
It’s not.
Structured and unstructured data have different characteristics: structured data is carefully curated, accurate, and secure. Unstructured data and LLMs are used for serendipitous exploration. Combining them is an exercise left to the developer.
A recent MIT study showed that using Generative AI with unstructured data increased speed-to-insight by 44% and quality by 20%. The study studied nontrivial critical thinking tasks like planning and exploring a data set by data scientists. It revealed that unstructured data helps analysts, data scientists, HR leaders, and executives make and communicate better decisions.
However, the study also showed that those LLM-generated answers were often wrong, and 68% of participants didn’t bother to check the answers. For GenAI, inaccuracies are partly by design: neural networks mimic how our brains work. Like humans, they make mistakes, hallucinate, and interpret questions incorrectly.
For most enterprise applications, such inaccuracies are unacceptable. Hybrid computing can help guide LLMs to accurate, secure, reliable, creative, and serendipitous responses. But how do you create these hybrid computing systems that leverage the best of both worlds?
Three elements of hybrid data computing
A hybrid computing system has three elements:
1. Hybrid query processing
2. Semantic data layer
3. Hybrid data indexing
Let’s explore each.
Hybrid query processing
Hybrid data computing aims to use structured and unstructured data as a single organism to provide accurate responses to natural language queries. Using structured data to guide LLM responses is the first element of a hybrid model.
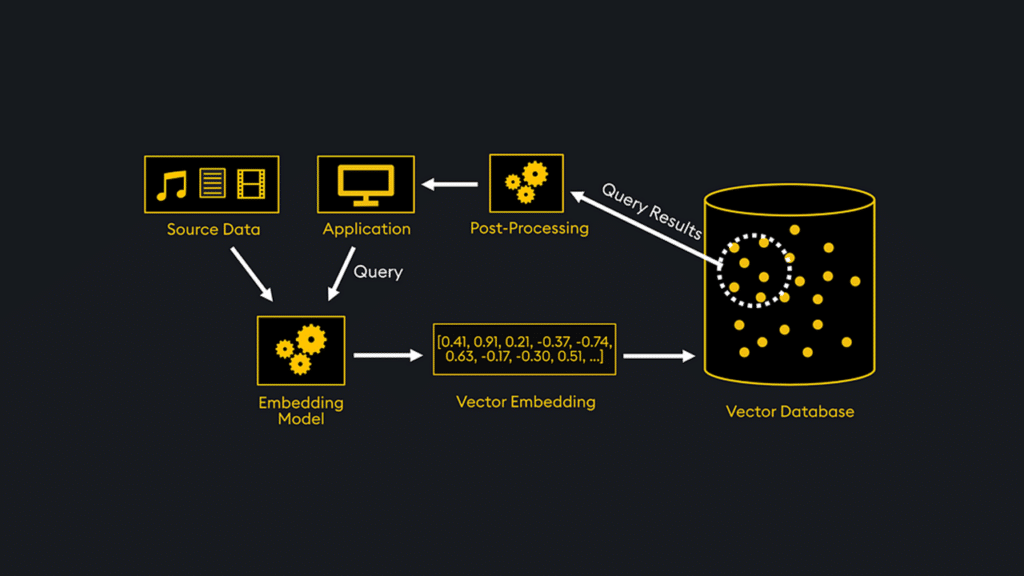
This demo explains how our vector database, KDB.AI, works with structured and unstructured data to find similar data across time and meaning, and extend the knowledge of Large Language Models.
For example, imagine our application answers prompts like “Why did my portfolio decline in value?” Using an LLM by itself yields a generic answer (on the left in the diagram below): market volatility, company news, currency fluctuations, or interest rate changes might be the source of a dip in your portfolio’s value.
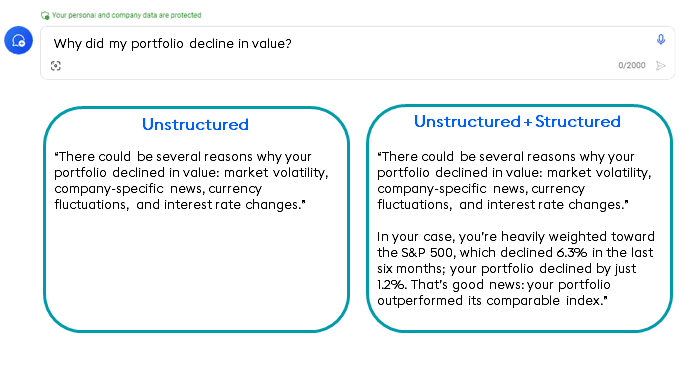
But we don’t want a generic LLM-generated answer – any public LLM can give us that. We want to know why MY portfolio declined and how MY performance relates to similar portfolios. That answer (on the right) is born by fusing structured data, similarity search, and LLM data in one hybrid system.
The first stage of answering this query is to examine the portfolio we’re interested in and compare it to similar portfolios. We find the account ID with a standard relational database lookup to do this. Then, we use vector embeddings to find portfolios similar to our own. This structured data query stage is shown at the top:
Once the context is established, the hybrid system forwards data to our LLM to formulate the language-based answer we see above as one answer. In this way, hybrid query processing combines accuracy, similarity, and prompt-based answers to provide GenAI answers powered by structured data.
Semantic data layer
When answering prompts with structured data, the software must understand what data it has on hand to query, its relationships to other data, and how to retrieve and combine it before passing that guidance to the LLM to answer questions. For that, we need a semantic data layer—a roadmap to the structured data the system has at hand. New research from Dataworld showed that LLM systems with this semantic understanding of data are three times more accurate than those without (54% versus 16% accuracy).
A semantic data layer is like a data treasure map that describes the semantics of the business domain and the physical database schema in a knowledge graph. It can include synonyms and labels not expressible in SQL to help convert natural language queries into the right SQL queries needed to satisfy the query.
Researchers argue that this context must be treated as a first-class citizen, managed with metadata like a master data management (MDM) tool or data catalog, or ideally in a knowledge graph architecture. Otherwise, the crucial context that provides accuracy would need to be managed ad hoc.
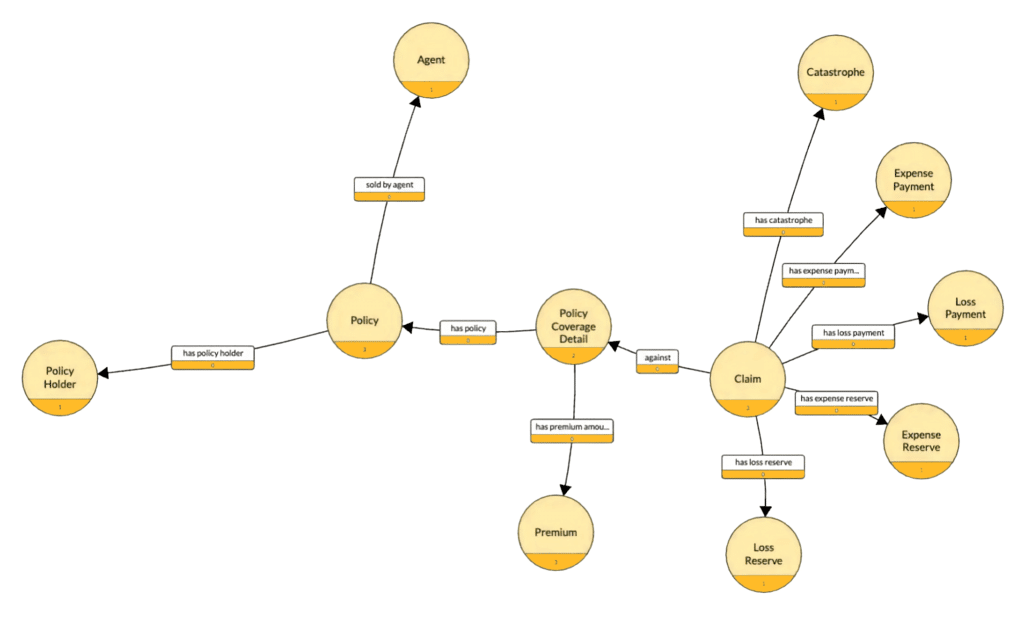
For example, to understand the relationships between an insurance claim, its policy payment, premiums, and profit and loss, you need to know how those data elements are related, like the portion of the graph below. Analysts and programmers traverse this graph to answer questions like, “What is the payout and cost of claim XYZ?” Once they find the claim and its associated policy, they can then understand payout, expenses, and reserves.
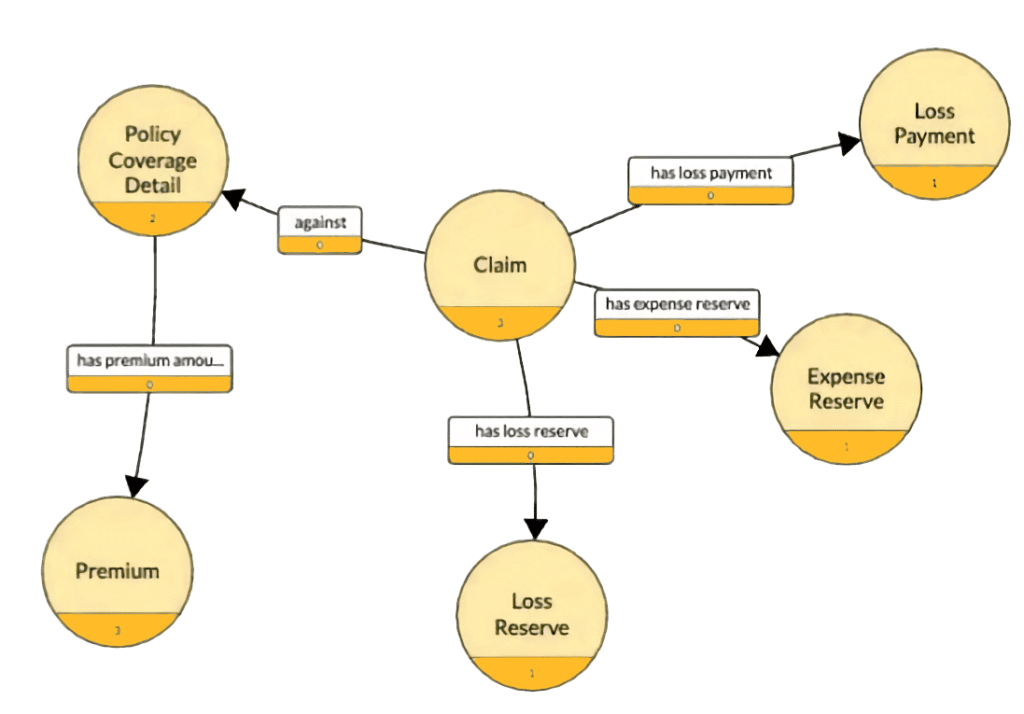
For our portfolio analysis question, a semantic data layer could help our hybrid query system understand the relationship between your portfolio and others, including the investment sector, portfolio size, risk, and other factors described in the semantic data layer. This helps ensure we have the right context and meaning in the data we provide the LLM.
Hybrid data indexing
The third requirement of hybrid computing is that it must work on constantly changing large data sets. Indexes are the fuel that powers all data-oriented computation. A hybrid data computing system must combine traditional structured data indexing, vector embeddings, and LLM data in one high-performance system (see diagram below).
Vector embeddings are a type of data index that uses numerical representations to capture the essence of unstructured data like text, images, or audio. They also extract the semantic relationships that can be integrated with a semantic data layer. Machine learning models create vector embeddings to help make unstructured data searchable.
Vector indexing refers to creating specialized data structures to enable efficient similarity search and retrieval of vector embeddings in a vector database. Like traditional database indexing, vector indexing aims to speed up queries by organizing the vector data to allow fast nearest-neighbor searches.
The elephant-in-the-room challenge associated with indexing unstructured data is that there’s so much of it. Financial services firms that analyze companies to make investment decisions must index thousands of pages of unstructured public from SEC filings like 10-K, 10-Q, 8-K, proxy statements, investor calls, and more.
The details of high-performance, scalable hybrid data indexing are outside the scope of this discussion. Still, it is the third foundational requirement of systems that process unstructured and structured data in one place. It is commonly done by “chunking” unstructured data into groups associated with similarly structured data and queried efficiently. Intelligent chunking uses vector embeddings to form a new type of hybrid index that combines unstructured and structured data in one optimized format.
Properly constructed hybrid computation, using hybrid indexing, can result in jaw-dropping economics. In one example using KDB.AI, a hybrid database, queries were found to be 100 times more efficient and 0.001% as expensive per query than non-optimized solutions. As a result, the solution was significantly more efficient, cost-effective and easier to use.
Accurate answers at scale
Hybrid data computing is an essential approach to the next wave of enterprise applications that use LLMs with carefully curated, structured data to produce more accurate, cost-effective answers at scale. The technologies to perform this kind of hybrid system are just now coming to market as vector databases mature and LLM use becomes more prevalent.
Learn how to integrate unstructured and structured data to build scalable GenAI applications with contextual search at our KDB.AI Learning Hub.

Overcoming AI Challenges with KDB.AI 1.1
In 2023, KX launched KDB.AI, a groundbreaking vector database and search engine to empower developers to build the next generation of AI applications for high-speed, time-based, multi-modal workloads. Used in industries such as Financial Services, Telecommunications, Manufacturing and more, KDB.AI is today recognized as the world’s leading vector database solution for enterprise customers.
In our latest update, we’re introducing several new features that will significantly improve vector performance, search reliability, and semantic relevance.
Let’s explore.
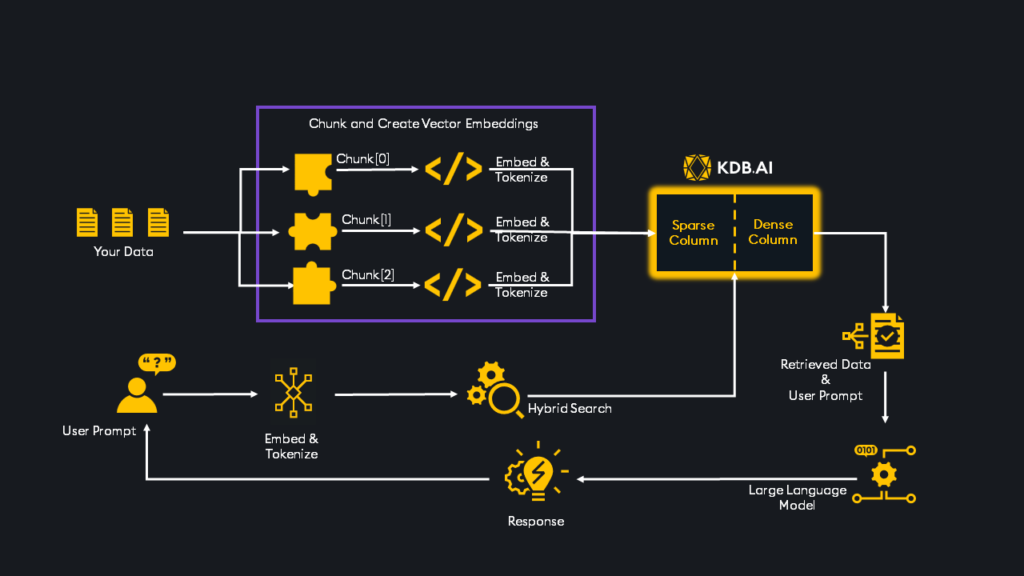
Hybrid Search
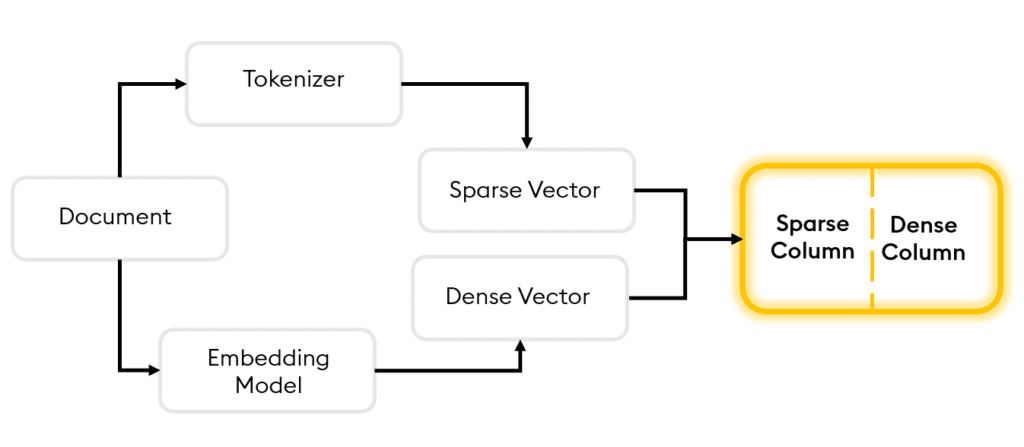
The first is Hybrid Search, an advanced tool that merges the accuracy of keyword-focused sparse vector search with the contextual comprehension provided by semantic dense vector search.
Sparse vectors predominantly contain zero values. They are created by passing a document through a tokenizer and associating each word with a numerical token. The tokens, along with a tally of their occurrences, are then used to construct a sparse vector for that document. This is incredibly useful for information retrieval and Natural Language Processing Scenarios where specific keyword matching must be highly precise.
Dense vectors in contrast predominantly contain non-zero values and are used to encapsulate the semantic significance, relationships and attributes present within the document. They are often used with deep learning models where the semantic meaning of words is important.
With KDB.AI 1.1, analysts can tweak the relative importance of sparse and dense search results via an alpha parameter, ensuring highly pertinent data retrieval and efficient discovery of unparalleled insight.
Example Use Case
Consider a financial analyst looking for specific information on a company’s performance in order to assess investment risk. The analyst might search for “Company X’s Q3 earnings report” in which a sparse vector search would excel.
However, the analyst might also be interested in the broader context, such as market trends, competitor performance, and economic indicators that could impact Company X’s performance. Dense vector search could be used to find documents that may not contain the exact keywords but are semantically related to the query.
For example, it might find articles discussing a new product launched by a competitor or changes in trade policies affecting Company X’s industry.
With Hybrid Search the analyst is afforded the best of both worlds, and ultimately retrieves a comprehensive set of information to assist with the development of their investment strategy.
Temporal Similarity Search
The second key feature is the introduction of Temporal Similarity Search (TSS), a comprehensive suite of tools for analyzing patterns, trends, and anomalies within time series datasets.
Comprising of two key components, Transformed TSS for highly efficient vector searches across massive time series datasets and Non-Transformed TSS, a solution for near real-time similarity search of fast-moving data, TSS enables developers to extract insights faster than ever before.
Transformed Temporal Similarity Search
Transformed Temporal Similarity Search is our patent-pending compression model designed to dimensionally reduce time-series windows by more than 99%. With Transformed TSS, KDB.AI can compress data points into significantly smaller dimensions whilst maintaining the integrity of the original data’s shape.
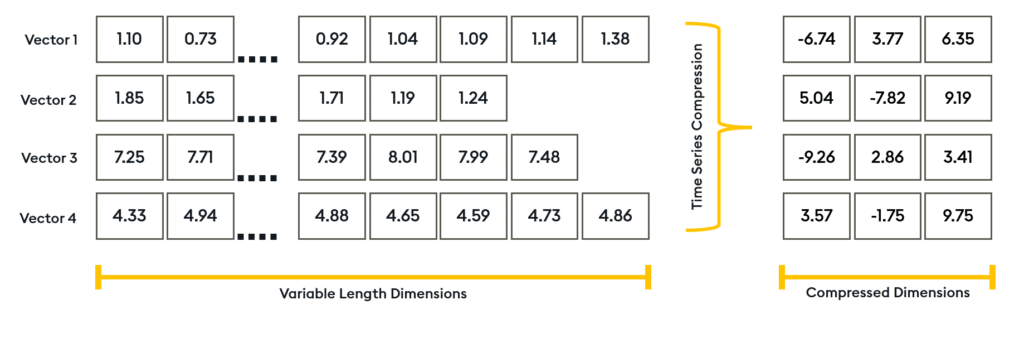
It also enables the compression of varying sized windows into a uniform dimensionality, in valuable when working with time series data of different sample rates and window sizes.
By doing so, Transformed TSS significantly reduces memory usage and disk space requirements to minimize computational burden. And with the ability to attach compressed embeddings to prebuilt Approximate Nearest Neighbor (ANN) indexes, developers can expect significant optimization of retrieval operations in large scale embeddings.
Example Use Case
Consider a multinational retail corporation that has been experiencing stagnant growth and is now looking for ways to improve their business strategies.
With Transformed TSS, they can perform detailed analysis of their time series user interaction data, including clicks, views, and engagement times. This allows them to uncover hidden patterns and trends, revealing optimal times and contexts for ad placement.
Applying a similar concept to their retail operations, they can segment purchase history data into time windows, resulting in advanced similarity searches that unveil subtle purchase patterns, seasonal variations, and evolving consumer preferences.
Armed with these insights, the corporation can fine-tune their marketing strategies, optimize stock levels, and predict future buying trends.
Non-Transformed Temporal Similarity Search
Non-Transformed Temporal Similarity Search is a revolutionary algorithm designed for conducting near real-time similarity search with extreme memory efficiency across fast moving time-series data. It provides a precise and efficient method to analyze patterns and trends with no need to embed, extract, or store vectors in the database.
Non-Transformed TSS enables direct similarity search on columnar time-series data without the need to define an Approximate Nearest Neighbor (ANN) search index. Tested on one million vectors, it was able to achieve a memory footprint reduction of 99% percent, and a 17x performance boost over 1K queries.
| Non-Transformed TSS | Hierarchical Navigable Small Worlds Index | |
| Memory Footprint | 18.8MB | 2.4GB |
| Time to Build Index | 0s | 138s |
| Time for Single Similarity Search | 23ms | 1ms (on prebuilt index) |
| Total Time for Single Search (5 neighbors) | 23ms | 138s+1ms |
| Total Time for 1000 searches (5 neighbors) | 8s | 139s |
Example Use Case
Consider a financial organization looking to enhance its fraud detection capabilities and better respond to the increased cadenced and sophistication of attacks. With millions of customers and billions of transaction records, the organization requires a computationally efficient solution that will scale on demand.
With Non-Transformed Temporal Similarity Search the organization can analyze transactions in near real-time, without the need to embed, extract or store incoming records into a database prior to analysis. Inbound transactions are compared against historical patterns in the same account, and those exhibiting a high degree of dissimilarity can be flagged for further investigation.
We hope that you are as excited as we are about the possibilities these enhancements bring to your AI toolkit. You can learn more by checking out our feature articles over on the KDB.AI Learning Hub then try them yourself by signing up for free at KDB.AI
Related Resources
The new dynamic data duo: Structured meets unstructured data to win on the generative AI playing field
On Wall Street, algorithmic trading has long been the revenue playing field: statistical analysis of micro-market movements helps traders predict how the profitability winds will blow at any millisecond. Profit, or “alpha,” is found by traders who create novel approaches to anticipate those price changes before their competitors win by analyzing the movement and momentum of structured data: numbers representing market prices, trades, and volume.
Today, the rise in technologies that make it cost-effective and easy to process unstructured data creates a new opportunity to gain an analytics edge: the combination of unstructured and structured data. This new source of insight is found in the connections between unstructured and structured data.
A new dynamic data duo, if you will.
Let’s explore this new insight opportunity and how firms can capitalize on it.
Structured data, meet unstructured data
Historically, unstructured data – found in PDF documents, on the web, or images, video and audio – has been explored but unexploited. Today, with the rise of generative AI and LLM technology, analyzing unstructured data creates new opportunities for insight.
In financial services, fusing structured market data with unstructured data like SEC filings, client interactions, analyst reports, social media sentiment, news, and more can reveal a new depth to insights. Combining structured and unstructured data is a revolutionary way to unlock data in ways never done before.
As we see below, unstructured data provides good, general advice about why an investment portfolio might decline in value, citing market volatility, news, currency fluctuations, and interest rate changes as reasons your portfolio might underperform.
But add individualized data from structured data sources, including account numbers, specific investments, their temporal performance, and indexes, and we get true insight (shown at right). We see why my portfolio declined. We see that my portfolio is outperforming its index. We see why my portfolio performed as it did. We see unique generative AI insight.

This dynamic duo of unstructured and structured data leverages three new computing elements.
Real-time unstructured data. Much of today’s structured data, like vital signs emitted from medical devices, are readily available. However, unstructured data for business applications, such as digital versions of doctors’ notes, are not as prevalent. But thanks to the rise in capabilities to analyze conversational data, these capabilities are becoming ubiquitous and cost-effective.
Digitized unstructured data. Thanks to the rise of generative AI, conversational messaging, and intelligent document processing technologies are more prevalent, less expensive, and easier to use than ever before. One area of this is conference call transcription and summarization, both available in tools like Zoom and Otter.ai. These tools emit a new source of digitized unstructured data useful for analysis.
Databases that fuse unstructured and structured data. Generative AI applications also require data management systems to connect and combine unstructured with structured data via vector embeddings, synthetic data sources, and data warehouses full of fused data to help prepare data for analysis. For example, KX’s new KDB.AI offering is designed to generate vector embeddings on unstructured documents and make them available for real-time queries.
The new dynamic duo and the role of LLMs
This dynamic data duo is not only at work on Wall Street; it’s also being used on Main Street applications. Consider healthcare. When you visit a hospital, doctors talk to you. That conversation generates unstructured data, with clues hidden inside your responses to the questions. Also, frontline staff takes your vital signs which provide a numerical read on how your body is actually performing.
The art of medicine is a doctor’s ability to connect numerical facts with clues revealed in conversations about how you feel. The National Institute of Health in Singapore implements this system today. Their system, Endeavor, combines conversations with vital signs in real-time to produce predictive, proactive insights.
For example, below, a machine learning algorithm evaluates unstructured doctor’s notes to identify references to abdominal pain reported by a patient.
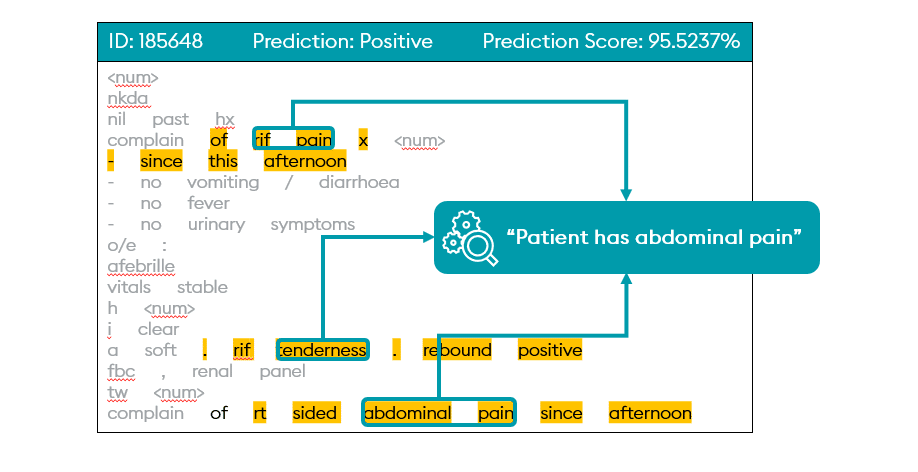
Structured data comes from medical devices that monitor patient vital signs, and unstructured data comes from digital versions of doctor notes, patient utterances, medical journals, and research, providing a 360-degree view of insight to help improve care.
This unstructured and structured data is sent in real time to AI algorithms that silently search for and predict the likelihood of dozens of potential ailments and diseases, including eye disease, cardiac abnormalities, pulmonary disease, neurological disorders, septic shock, and oncology.
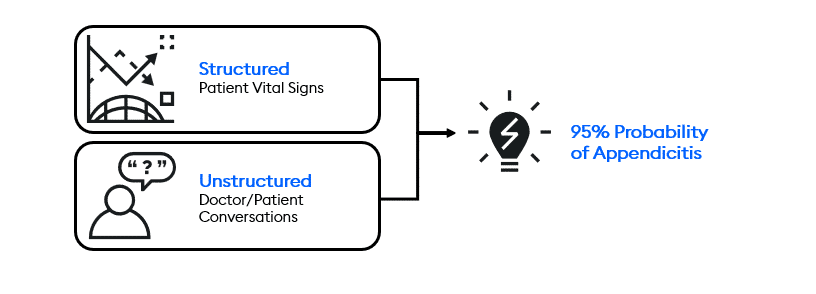
Predictions are returned to front-line medical staff who can make smarter recommendations. In this case, AI predicts that this patient is 95% likely to have appendicitis.
A new dynamic duo, a new source of insights
Traditionally, the two “data worlds” of unstructured and structured data did not collide. But today, unstructured data is easier and more cost-effective to extract than ever before, which makes it possible for the first time to easily combine with structured data to generate new insights.
This new dynamic duo of data affords new opportunities for insight hidden between conversational data and real-time streaming data, from Wall Street to Main Street. Databases designed to combine structured and unstructured data to unlock new hidden insights are the key arbiters of these data insights.
Related Resources
Build RAG-Enabled Applications with LlamaIndex and KDB.AI
Large Language Models (LLMs) have transformed natural language understanding, powering applications like chatbots, question answering, and summarization. However, their static datasets can limit relevance and accuracy. Retrieval-Augmented Generation (RAG) addresses this by enriching LLMs with up-to-date external data, enhancing response quality and contextual relevance. RAG is a powerful workflow, but building RAG-enabled applications is complex, requiring multiple steps and a scalable infrastructure.
To simplify this process, we’re excited to introduce the integration of KDB.AI with LlamaIndex, an open-source framework that streamlines the ingestion, storage, and retrieval of datasets for RAG applications. This integration enables developers to create sophisticated RAG-enabled applications with ease and efficiency.
In this blog post, we will explain how LlamaIndex and KDB.AI work together to enable RAG solutions and showcase some potential enterprise use cases that can benefit from this integration.
How Does LlamaIndex Enable RAG Solutions?
LlamaIndex is a data framework for building LLM-based applications, it specializes in augmenting LLMs with private or domain-specific data. LlamaIndex offers several types of tools and integrations to help users quickly develop and optimize RAG pipelines:
- Data Loaders: Ingest your data from its native format. There are many connectors available including for .csv, .docx, HTML, .txt, PDF, PPTX, Pandas DataFrames, and more.
- Parsing: Chunking data into smaller and more context specific nodes can greatly improve the results of your RAG application.
- Embeddings: Transforming your data into vector embeddings is a key step in the RAG process. LlamaIndex integrates with many embedding models including OpenAI embedding models, Hugging Face Embeddings, LangChain Embeddings, Gemini Embeddings, Clip Embeddings, and many more.
- Vector Stores / Index: Store embeddings within vector databases like KDB.AI to perform fast and accurate retrieval of relevant data to augment the LLM.
- Hyperparameter Tuning: Optimize both chunk size and the number of top-k retrieved chunks to ensure your RAG pipeline generates the best possible results.
- Retrievers: LlamaIndex offers a variety of retrievers to get the most relevant data from the index. Some examples are, Auto-Retrieval, Knowledge Graph retriever, hybrid retriever (BM25), Reciprocal Rerank Fusion retriever, Recursive Retriever, Ensemble Retriever, etc.
- Postprocessors: LlamaIndex has many options for postprocessing retrieved data ranging from keyword matching, reranking, recency filtering, time-weighted reranking, sentence windows, long context reordering (fixes lost in the middle problem), prompt compression, retrieve surrounding nodes and others.
- Data Agents: Agents are LLM-powered knowledge workers that use tools and functions to complete specific tasks. LlamaIndex supports and integrates with several agent frameworks such as “OpenAIAgent”.
- Evaluation: Evaluate both the retrieval and generation phases of RAG with modules to test retrieval precision, augmentation precision, answer consistency, answer accuracy and more.
- Llama Packs: Llama Packs are prepackaged modules to help users quickly compose an LLM application. Llama Packs can be initialized and run out-of-the-box or used as templates to modify to your use-case. You can see available Llama Packs on the Llama Hub. Examples include RAG pipelines, resume screener, and moderation packages.
KDB.AI Integration with LlamaIndex
KDB.AI is a high-performance vector database optimized for machine learning, natural language processing, and semantic search at scale. It stores and queries vector embeddings, with the ability to attach embeddings to a variety of indexes to facilitate rapid vector search and retrieval.
LlamaIndex can be used orchestrate ingestion, preprocessing, metadata tagging, and embedding for incoming data or the user’s query. Its integration with KDB.AI enables a variety of retrieval methods to find contextually relevant information from the KDB.AI vector store. The retrieved information can then be postprocessed and used to augment the LLM’s generated output, resulting in a more precise and contextually relevant response to the user’s question.
The following diagram illustrates the workflow of LlamaIndex and KDB.AI for RAG solutions:
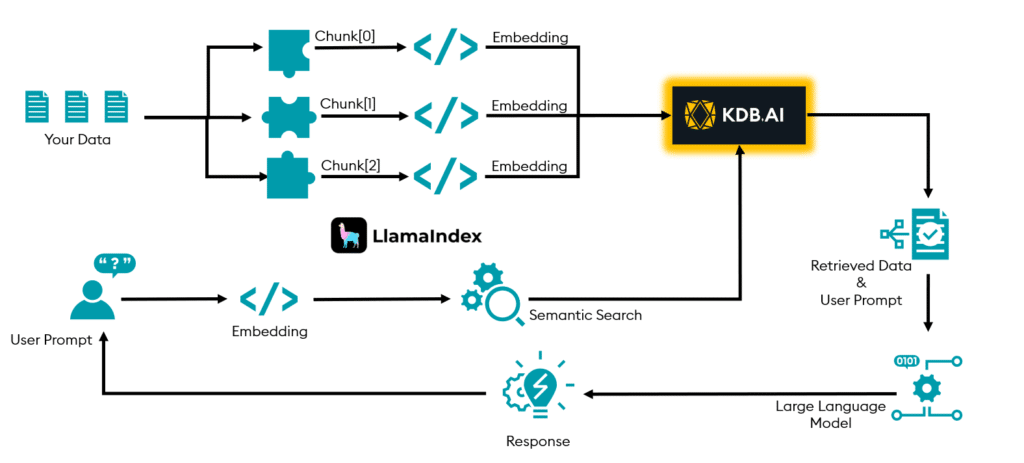
LlamaIndex has functionality to help orchestrate each phase in the above diagram while still giving the user the flexibility to implement the RAG workflow in the best interest of the use-case.
Potential Use Cases
By combining LlamaIndex and KDB.AI, developers can leverage the power of RAG solutions for a variety of applications, such as:
- Document Q&A: You can use LlamaIndex to ingest and index your unstructured data sources, such as manuals, reports, contracts, etc., and convert to vector embeddings. Then, you can use KDB.AI to store and query the vector embeddings at scale, using natural language queries. This way, you can provide fast and accurate answers to your users’ questions, without requiring them to read through lengthy documents.
- Data Augmented Chatbots: You can use LlamaIndex to connect and structure your semi-structured data sources, such as APIs, databases, etc. Then, you can use KDB.AI to search and rank the relevant data items based on the user’s input and the chatbot’s context. This way, you can enhance your chatbot’s capabilities and provide more personalized and engaging conversations to your users.
- Knowledge Agents: You can use LlamaIndex to index your knowledge base and tasks, such as FAQs, workflows, procedures, etc. Then, you can use KDB.AI to store and query the vector embeddings, using natural language commands. This way, you can create automated decision machines that can perform tasks based on the user’s input, such as booking appointments, ordering products, resolving issues, etc.
- Structured Analytics: You can use LlamaIndex to ingest and index your structured data sources, such as spreadsheets, tables, charts, etc. Then, you can use KDB.AI to search and rank the relevant data rows or columns based on the user’s natural language query. This way, you can provide easy and intuitive access to your data analytics, without requiring the user to learn complex syntax or tools.
- Content Generation: You can use LlamaIndex to ingest and index your existing content sources, such as blogs, articles, books, etc. Then, you can use KDB.AI to search and rank the most similar or relevant content items based on the user’s input or topic. This way, you can generate new and original content, such as summaries, headlines, captions, etc., using the LLM’s generation capabilities.
In this blog we have discussed how LlamaIndex and KDB.AI work together to empower developers to build RAG-enabled applications quickly and at scale. By integrating LlamaIndex and KDB.AI, developers can augment LLMs with contextually accurate information, and in turn, provide more precise and contextually relevant response to end user questions.
To find out more check out our documentation today!
Related Resources
Transforming Enterprise AI with KDB.AI on LangChain
Artificial Intelligence (AI) is transforming every industry and sector, from healthcare to finance, from manufacturing to retail. However, not all AI solutions are created equal. Many of them suffer from limitations such as poor scalability, low accuracy, high latency, and lack of explainability.
That’s why we’re excited to announce the integration of KDB.AI and LangChain, two cutting-edge technologies designed to overcome these challenges and deliver unparalleled capabilities for enterprise AI via a simple and intuitive architecture that doesn’t require complex infrastructure or costly expertise.
In this blog post, I’ll give you a brief overview of each technology, discuss typical use cases, and then show you how to get started. Let’s begin.
What is KDB.AI?
KDB.AI is an enterprise grade vector database and analytics platform that enables real-time processing of both structured and unstructured time-oriented data. It’s based on kdb+, the world’s fastest time-series database, which is widely used by leading financial institutions for high-frequency trading and market data analysis.
With KDB.AI, developers can seamlessly scale from billions to trillions of vectors without performance degradation, thanks to its distributed architecture and efficient compression algorithms. It also supports various data formats, such as text, images, audio, video, and more.
With KDB.AI you can:
- Create an index of vectors (Flat, IVF, IVFPQ, or HNSW).
- Append vectors to an index.
- Perform fast vector similarity search with optional metadata filtering.
- Persist an index to disk.
- Load an index from disk.
To learn more about KDB.AI, visit our documentation site.
What is LangChain?
LangChain is an open-source framework designed to simplify the creation of applications powered by language models. At its core, LangChain enables you to “chain” together components, acting as the building blocks for natural language applications such as Chatbots, Virtual Agents and document summarization.
LangChain doesn’t rely on traditional NLP pipelines, such as tokenization, lemmatization, or dependency parsing, instead, it uses vector representations of natural language, such as word embeddings, sentence embeddings, or document embeddings, which capture the semantic and syntactic information of natural language in a compact and universal way.
To learn more about LangChain, visit their documentation site.
How KDB.AI and LangChain work together
The integration of KDB.AI and LangChain empowers developers with real-time vector processing capability and state-of-the-art NLP models. This combination opens new possibilities and use cases for enterprise AI, such as:
- Enterprise search: You can use LangChain to encode text documents into vectors, and then use KDB.AI to index and query them using advanced quad-search capabilities, combining keyword, fuzzy, semantic, and time-based search. This way, you can create a powerful and flexible enterprise search capability that can handle any type of query and return the most relevant results.
- RAG at scale: You can use LangChain to implement Retrieval Augmented Generation (RAG), a novel technique that combines a retriever and generator to produce rich and diverse text outputs. You can then use KDB.AI to store and retrieve the vectors of the documents that are used by the retriever, enabling you to scale RAG to large and complex domains and applications.
- Anomaly detection: You can use LangChain to detect anomalies in text data, such as spam, fraud, or cyberattacks, using pre-trained or fine-tuned models. You can then use KDB.AI to store and analyze the vectors of the anomalous texts, using clustering, classification, or regression techniques, to identify the root causes and patterns.
- Sentiment Analysis: You can use LangChain to perform sentiment analysis on text data, such as customer reviews, social media posts, or news articles, using pre-trained or fine-tuned models. You can then use KDB.AI to store and visualize the vectors of the texts, using dashboarding, charting, or reporting tools, to gain insights into the opinions and emotions of customers, users, or audiences.
- Text summarization: You can use LangChain to generate concise and informative summaries of long text documents, such as reports, articles, or books, using pre-trained or fine-tuned models. You can then use KDB.AI to store and compare the vectors of the original and summarized texts, using similarity or distance metrics, to evaluate the quality and accuracy of the summaries.
How to get started with KDB.AI and LangChain
If you’re interested in trying out KDB.AI on LangChain, I invite you to follow these simple steps.
- Sign up for a free trial of KDB.AI.
- Set up your environment and configure pre-requisites.
- Work through the sample integration.
We also have some great resources from our evangelism team, including samples over on the KDB.AI learning hub and regular livestreams. And should you have any feedback, questions, or issues a dedicated team over on our Slack community.
Happy Coding!


