




In the era of big data, industries such as finance and manufacturing generate large volumes of time series data every day. This data, unlike classical relational data, is updated more frequently, with new data points continuously generated. This necessitates the need for specialized time series databases that meet the stringent requirements of read/write throughput and latency.
In a recent paper titled “Benchmarking Specialized Databases for High-frequency Data” researchers Fazl Barez (University of Edinburgh), Paul Bilokon, and Ruijie Xiong (Imperial College London) conducted a comprehensive performance benchmark evaluation of four specialized solutions: ClickHouse, InfluxDB, kdb+, and TimescaleDB.
Setup
Using a personal PC, equipped with an Intel i7-1065G7 CPU and 16GB of RAM, the researchers defined a scenario in which each database would be evaluated to store trade and order book records derived from a 25GB cryptocurrency feed.
Benchmarks were divided into five categories: Trades, Order Book, Complex Queries, Writing, and Storage Efficiency.
- The Trades category included calculations on trades data commonly used in the industry such as average trading volume and Volume Weighted Average Price (VWAP)
- The Order Book category involved actions and analysis of the order book data that are frequently used such as bid/ask spread and National Best Bid and Offer (NBBO)
- Benchmarks that required complicated queries with joins and nested queries such as mid-quote returns were classified in the Complex Query category.
- The remaining categories focused on “Bulk Writing” tasks and “Storage Efficiency”
The main metric for each benchmark was the query latency, or the amount of time between sending the query to the server and receiving the results. Query latency was derived from the built-in timers of each database solution.
The process was automated via Python, which made a connection with the database hosted on the local machine. All databases saved their data in SSD and adequate memory was made available during execution. It should be noted that each database was tested individually, and results were based on the average result from 10 executions.
Results
As illustrated in the table below, the results of the experiment concluded that kdb+ had the best overall performance among all tested solutions and therefore the most suitable database for financial analysis application of time series data.
kdb+ was able to quickly ingest data in bulk, with good compression ratios for storage efficiency. It also demonstrated low query latency for all benchmarks including read queries, computationally intensive queries, and complex queries.
| Benchmark | kdb+ | InfluxDB | TimescaleDB | ClickHouse |
| Query Latency (ms) | ||||
| Write perf (day trades\order book data to persistent storage) | 33889 | 324854 | 53150 | 765000 |
| Avg trading volume 1 min\Day | 81 | 93 | 469 | 272 |
| Find the highest bid price in a week | 94 | 146 | 3938 | 962 |
| National Best Bid and Offer for day | 34 | 191 | 1614 | 454 |
| Volume Weighted Average Price 1 min\Day | 75 | 12716 | 334 | 202 |
| Bid/Ask spread over a day | 1386 | 623732 | 2182 | 14056 |
| Mid-quote returns 5 min\Day | 113 | 99 | 1614 | 401 |
| Volatility as standard deviation of execution price returns 5 min\Day | 51 | 2009 | 324 | 190 |
STAC-M3 Financial Services Benchmarking
Tested to be 29x faster than Cassandra and 38x faster than MongoDB, Kdb+ holds the record for 10 out of 17 benchmarks in the Antuco suite and 9 out of 10 benchmarks for the Kanaga suite in the STAC-M3 benchmark, the industry standard for time series data analytics benchmarking in financial services.
STAC-M3 represents one of the only truly independently audited set of data analytics benchmarks available to the financial services industry and acts as a valuable service to FSI businesses by “cutting through” the proprietary technical marketing benchmarks available from each technology vendor.
Typical Kdb+/tick Architecture:
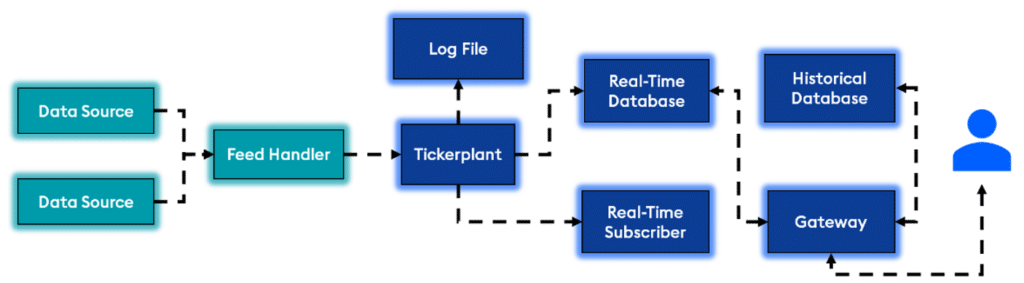
The kdb+/tick architecture is designed from the ground up to capture, process, and analyse real-time and historical data.
- Data is ingested by a feed handler, which translates the content into a kdb+ format.
- A Tickerplant receives the formatted data and writes to the log file, real-time subscriber, and real-time database.
- Intraday data is persisted to the historical database at the end of the day, and the real-time database is flushed along with the log file to accept new data.
- A gateway is used to handle user queries to the database. (This could be in the form of real-time, historical, or a combination of both).
The superior performance of kdb+ in handling high-frequency data underscores the importance of choosing the right database for time-series analysis. And with our latest updates, we have once again pushed the boundaries of speed, achieving an additional 50% reduction in ingestion times through multithreaded data loading and a fivefold increase in performance when working with high-volume connections.
Read the paper here: [2301.12561] Benchmarking Specialized Databases for High-frequency Data (arxiv.org) then try it yourself by signing up for your free 12-month personal edition of kdb+



