



Turbocharging Data Analytics with KX on Databricks
Data analysts know, that whether in finance, healthcare, manufacturing or any other industry, efficient handling of time series data helps derive better decision making and enhanced business intelligence. The process however can often be cumbersome and resource intensive due to language limitations, code complexity and high-dimensional data.
In this blog, we will explore the partnership between KX and Databricks and understand how the technologies complement each other in providing a new standard in quantitative research, data modelling and analysis.
Understanding the challenge
SQL, despite its widespread use, often stumbles when interrogating time-based datasets, struggling with intricate temporal relationships and cumbersome joins. Similarly, Python, R, and Spark drown in lines of code when faced with temporal analytics, especially when juggling high-dimensional data.
Furthermore, companies running on-premises servers will often find that they hit a computational ceiling, restricting the types of analyses that can be run. Of course, procurement of new technology is always possible, but that often hinders the ability to react to fast paced market changes.
By leveraging the lightning-fast performance of kdb+ and our Python library (PyKX), Databricks users can now enhance their data-driven models directly within their Databricks environment via our powerful columnar and functional programming capability, without requiring q language expertise.
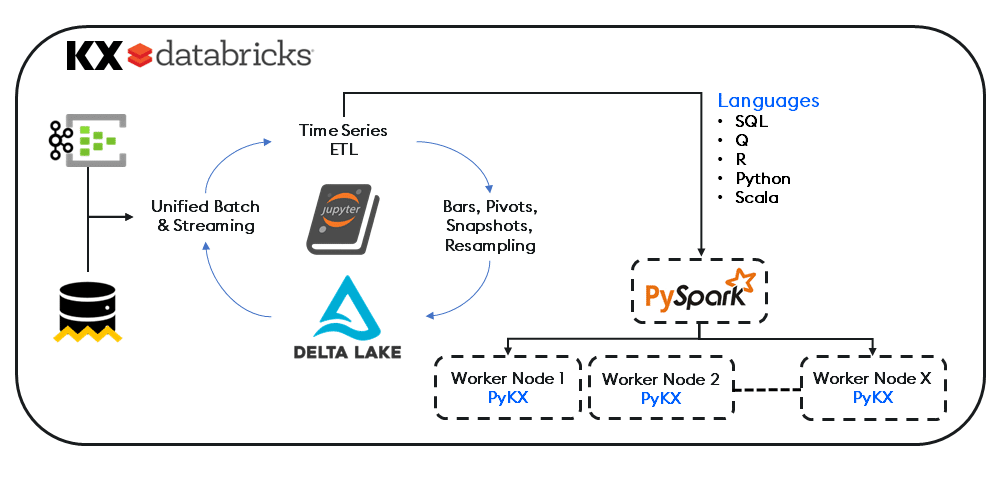
Integrating into PySpark and existing data pipelines as an in-memory time-series engine, KX eliminates the need for external dependencies, connecting external sources to kdb+ using PyKX, Pandas or our APIs. And with direct integration into the Databricks Data Intelligence Platform, both Python and Spark workloads can now execute on native Delta Lake datasets, analysed with PyKX for superior performance and efficiency.
The net result is a reduction in hours spent with on-premises orchestration, efficiencies in parallelization through Spark and prominent open-source frameworks for ML Workflows.
In a recent transaction cost analysis demo, PyKX demonstrated 112x faster performance with 1000x less memory when compared to Pandas. This was working with Level 1 equities and trade quotes sourced from a leading data exchange and stored natively in Databricks on Delta Lake.
| Syntax | Avg Time | Avg Dev | runs | loops | Total Memory | Memory Increment |
| Pandas | 2.54 s | 24.7 ms | 7 | 1 | 3752.16 Mib | 1091.99 Mib |
| PyKX | 22.7 ms | 301 us | 7 | 10 | 2676.06 Mib | 1.16 Mib |
These results show a remarkable reduction in compute resource and lower operating costs for the enterprise. Analysts can import data from a variety of formats either natively or via the Databricks Data Marketplace, then use managed Spark clusters for lightning-fast ingestion.
Other Use Case Examples
- Large Scale Pre and Post Trade Analytics
- Algorithmic Trading Strategy Development and Backtesting
- Comprehensive Market Surveillance and Anomaly Detection
- Trade Lifecycle and Execution Analytics
- High Volume Order Book Analysis
- Multi-Asset Portfolio Construction and Analysis
- Counterparty Risk Analysis in High-Volume Trading Environments
In closing, the combined strengths of KX and Databricks offer significant benefits in data management, sophisticated queries, and analytics on extensive datasets. It fosters collaboration across departments by enabling access to a unified data ecosystem used by multiple teams. And by integrating ML algorithms into the vast datasets managed with Databricks Lakehouse, analysts can uncover more profound and timely insights, predict trends, and improve mission-critical decision making.
To find out more, read the blog: “KX and Databricks Integration: Advancing Time-series Data Analytics in Capital Markets and Beyond” or download our latest datasheet.
Related Resources

Introducing The KX Delta Platform 4.8.1
Built on top of kdb+, the world’s fastest time-series database, the KX Delta Platform enables enterprises to design, build and deploy, highly performant data capture & processing systems that meets today’s demanding security standards. With out of the box LDAP authorization, data encryption and permission control, the KX Delta platform is also subjected to regular code security review and remediation. Our latest update includes several new innovations, including integration of kdb+ 4.1, object storage as an option for the Historical Database (HDB), our Python interface (PyKX) and SQL.
Let’s explore.
The KX Delta Platform consists of the following key components.
| Dashboards | An easy-to-use, drag and drop visualization tool. |
| Analyst | An enterprise grade visual environment with identity and access management to manage, manipulate and explore massive datasets in real-time. |
| Control & Stream | A client-server application to design, build, deploy and manage data capture/streaming systems. Including access control, entitlement, and encryption. |
| kdb+ | A time-series vector database (TSDB) with in-memory (IMDB) capabilities to provide data scientists and developers with a centralized high-performance solution for real-time and multi-petabyte datasets. |
The latest updates to kdb+ (v4.1) include significant advancements in performance, security, and usability, empowering developers to turbo charge workloads, fortify transmissions and improve storage efficiency.
Updates include:
- Peach/Parallel Processing with work-stealing to ensure that idle processors intelligently acquire tasks from busy ones.
- Multithreaded Data Loading to reduce large dataset ingestion by up to 50%
- Enhanced TLS and OpenSSL to safeguard sensitive real-time data exchanges, IPC and HTTP multithreaded input queues.
- Enhanced at rest compression to ensure storage efficiency without compromising data access speed.
To find out more: please read out blog: Discover kdb+’s New Features on staging.kx.com
PyKX and SQL Integration
For Python developers, the integration of PyKX into the Delta Platform unlocks the speed and power of kdb+ for data processing and storage. It empowers Python developers (e.g. Data Scientists) to apply analytics (using PyKX library functions) against vast amounts of data, both in memory and on disk in a fraction of the time when compared to standard Python environments. Similarly, for q developers, the integration of PyKX opens the door to a wealth of new data science workloads and Python based analytics.
ANSI SQL introduces a full relational database management system (RDBMS) for end users not proficient in q. Support is included for Operators, Functions, Data and Literals, Select Statements, Table Creation, Modification and Deletion.
To find out more or enrol on one of our PyKX/SQL courses, please visit the KX Learning Hub
Persisting the HDB to object storage
In a typical kdb+ architecture, end of day data is persisted to the Historical Database (HDB) to free system memory. Over time the size of the HDB and its associated storage can be significant. To help manage costs, the KX Delta Platform can now offer object storage as an option, providing a new modality for inexpensive, durable, long-term storage strategies. This offers the benefits of highly available and infinitely scalable cloud-based solutions and ensures that enterprise customers can still retrieve long-term historical datasets.
Typical Use Cases
The KX Delta Platform supports the rapid development of kdb+ powered solutions with the hardening needed in a secure, on-prem platform.
- Data integration and fusion: Integrate and analyze data from multiple intelligence sources to create a comprehensive data landscape of subversive activities and networks.
- Real-time intelligence and analysis: Process and analyze data in real time using multiple data streams to identify threats and respond quickly.
- Pattern recognition and anomaly detection: Analyze historical and current data to identify patterns, trends, and anomalies.
To find out more contact sales@devweb.kx.com
Related Resources
PyKX open source, a year in review
Initially conceived as a comprehensive integration between Python and kdb+/q PyKX has gone from strength-to-strength both in terms of user adoption and functionality since the first lines of code were written in January 2020. During the first years of development, PyKX was a closed source library available to clients via closely guarded credentials unique to individual organisations.
In May of last year this changed when we announced PyKX as an open source offering available via PyPi and Anaconda, with the source code available on Github. Since then, across these two distribution channels the library has been downloaded more than 200,000 times.
In this blog we will run through how the central library has evolved since that initial release in response to user feedback.
What’s remained consistent?
Since initial release the development team have taken pride in providing a seamless developer experience for users working at the interface between Python and q. Our intention is to provide as minimal a barrier for entry as possible by providing Python first methods without hiding the availability and power of q. Coupled with this the team has been striving to make PyKX the go-to library for all Python integrations to q/kdb+.
These dual goals are exemplified by the following additions/changes since the open-source release:
- PyKX under q as a replacement of embedPy moved to production usage in Release 2.0.0
- Addition of License Management functionality for manual license interrogation/management alongside a new user driven licenses installation workflow outlined here. Additionally expired or invalid licenses will now prompt users to install an updated license.
- When using a Jupyter Notebooks, tables, dictionaries and keyed tables now have HTML representations increasing legibility.
- PyKX now supports kdb+ 4.1 following the release on February 13th 2024
What’s changed?
Since being open-sourced, PyKX has seen a significant boost in development efforts. This increase is due to feedback on features from users and responses to the issues they commonly face. A central theme behind requests from clients and users has been to expand the Python first functionality provided when interacting with PyKX objects and performing tasks common for users of kdb+/q.
This can be seen through additions in the following areas:
- Increases in the availability of Pandas Like API functionality against “pykx.Table” objects including the following methods: merge_asof, set_index, reset_index, apply, groupby, agg, add_suffix, add_prefix, count, skew and std.
- Interactions with PyKX vectors and lists have been improved considerably allowing users to:
- Append and Extend new elements to their vectors using Python familiar syntax
- Run analytics and apply functions to their vectors in a Python first manner
- PyKX atomic values now contain null/infinity representations making the development of analytics dependent on them easier. In a similar vein we have added functionality for the retrieval of current date/time information. See here for an example.
- In cases where PyKX does not support a type when converting from Python to q we’ve added a register class which allows users to specify custom data translations.
- The addition of beta features for the following in PyKX
- The ability for users to create and manage local kdb+ Partitioned Databases using a Python first API here.
- The ability for users with existing q/kdb+ server infrastructure to remotely execute Python code on a server from a Python session. Full documentation can be found here.
What’s next?
The central principles behind development of the library haven’t changed since our initial closed source release and the direction of development will continue to be driven by user feedback and usage patterns that we see repeated in client interactions. On our roadmap for 2024 are developments in the following areas:
- Streaming use-cases allowing users in a Python first manner to get up and running with data ingestion and persistence workflows.
- Enhancements to the performance of the library in data conversions to and from our supported Python conversion types.
- Expansion to the complexity of data-science related functions and methods supported by PyKX to allow for efficient data analysis.
Conclusion
Over the last year, significant progress in the library has greatly enhanced PyKX’s usability. This progress was largely influenced by daily interactions with the development community using PyKX. By making the library available on PyPi, Anaconda, and the KX GitHub, we’ve accelerated development and deepened our understanding of what users want to see next with PyKX.
If you would like to be involved in development of the library, I encourage you to open issues for the features that you would like to see or to open a pull request to have your work incorporated in an upcoming release.
Related Resources
Benchmarking Specialized Databases for High-frequency Data
In the era of big data, industries such as finance and manufacturing generate large volumes of time series data every day. This data, unlike classical relational data, is updated more frequently, with new data points continuously generated. This necessitates the need for specialized time series databases that meet the stringent requirements of read/write throughput and latency.
In a recent paper titled “Benchmarking Specialized Databases for High-frequency Data” researchers Fazl Barez (University of Edinburgh), Paul Bilokon, and Ruijie Xiong (Imperial College London) conducted a comprehensive performance benchmark evaluation of four specialized solutions: ClickHouse, InfluxDB, kdb+, and TimescaleDB.
Setup
Using a personal PC, equipped with an Intel i7-1065G7 CPU and 16GB of RAM, the researchers defined a scenario in which each database would be evaluated to store trade and order book records derived from a 25GB cryptocurrency feed.
Benchmarks were divided into five categories: Trades, Order Book, Complex Queries, Writing, and Storage Efficiency.
- The Trades category included calculations on trades data commonly used in the industry such as average trading volume and Volume Weighted Average Price (VWAP)
- The Order Book category involved actions and analysis of the order book data that are frequently used such as bid/ask spread and National Best Bid and Offer (NBBO)
- Benchmarks that required complicated queries with joins and nested queries such as mid-quote returns were classified in the Complex Query category.
- The remaining categories focused on “Bulk Writing” tasks and “Storage Efficiency”
The main metric for each benchmark was the query latency, or the amount of time between sending the query to the server and receiving the results. Query latency was derived from the built-in timers of each database solution.
The process was automated via Python, which made a connection with the database hosted on the local machine. All databases saved their data in SSD and adequate memory was made available during execution. It should be noted that each database was tested individually, and results were based on the average result from 10 executions.
Results
As illustrated in the table below, the results of the experiment concluded that kdb+ had the best overall performance among all tested solutions and therefore the most suitable database for financial analysis application of time series data.
kdb+ was able to quickly ingest data in bulk, with good compression ratios for storage efficiency. It also demonstrated low query latency for all benchmarks including read queries, computationally intensive queries, and complex queries.
| Benchmark | kdb+ | InfluxDB | TimescaleDB | ClickHouse |
| Query Latency (ms) | ||||
| Write perf (day trades\order book data to persistent storage) | 33889 | 324854 | 53150 | 765000 |
| Avg trading volume 1 min\Day | 81 | 93 | 469 | 272 |
| Find the highest bid price in a week | 94 | 146 | 3938 | 962 |
| National Best Bid and Offer for day | 34 | 191 | 1614 | 454 |
| Volume Weighted Average Price 1 min\Day | 75 | 12716 | 334 | 202 |
| Bid/Ask spread over a day | 1386 | 623732 | 2182 | 14056 |
| Mid-quote returns 5 min\Day | 113 | 99 | 1614 | 401 |
| Volatility as standard deviation of execution price returns 5 min\Day | 51 | 2009 | 324 | 190 |
STAC-M3 Financial Services Benchmarking
Tested to be 29x faster than Cassandra and 38x faster than MongoDB, Kdb+ holds the record for 10 out of 17 benchmarks in the Antuco suite and 9 out of 10 benchmarks for the Kanaga suite in the STAC-M3 benchmark, the industry standard for time series data analytics benchmarking in financial services.
STAC-M3 represents one of the only truly independently audited set of data analytics benchmarks available to the financial services industry and acts as a valuable service to FSI businesses by “cutting through” the proprietary technical marketing benchmarks available from each technology vendor.
Typical Kdb+/tick Architecture:
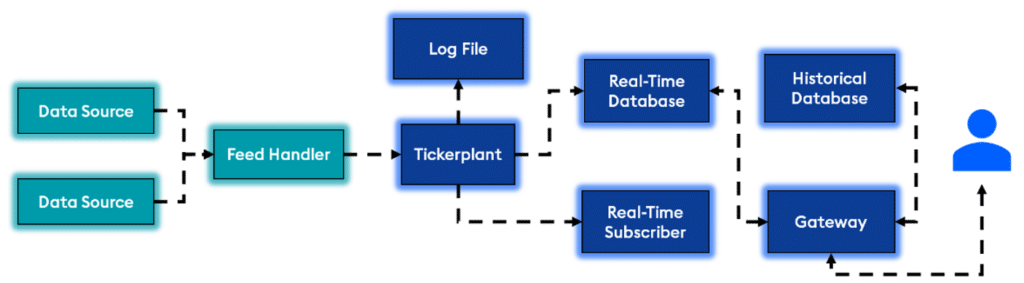
The kdb+/tick architecture is designed from the ground up to capture, process, and analyse real-time and historical data.
- Data is ingested by a feed handler, which translates the content into a kdb+ format.
- A Tickerplant receives the formatted data and writes to the log file, real-time subscriber, and real-time database.
- Intraday data is persisted to the historical database at the end of the day, and the real-time database is flushed along with the log file to accept new data.
- A gateway is used to handle user queries to the database. (This could be in the form of real-time, historical, or a combination of both).
The superior performance of kdb+ in handling high-frequency data underscores the importance of choosing the right database for time-series analysis. And with our latest updates, we have once again pushed the boundaries of speed, achieving an additional 50% reduction in ingestion times through multithreaded data loading and a fivefold increase in performance when working with high-volume connections.
Read the paper here: [2301.12561] Benchmarking Specialized Databases for High-frequency Data (arxiv.org) then try it yourself by signing up for your free 12-month personal edition of kdb+
Related Resources
Discover kdb+ 4.1’s New Features
With the announcement of kdb+ 4.1, we’ve made significant updates in performance, security, and usability, empowering developers to turbo charge workloads, fortify transmissions and improve storage efficiency. In this blog, we’ll explore these new features and demonstrate how they compare to previous versions.
Let’s begin.
Peach/Parallel Processing Enhancements
“Peach” is an important keyword in kdb+, derived from the combination of “parallel” and “each”. It enables the parallel execution of a function on multiple arguments.
In kdb+ 4.1 the ability to nest “peach” statements now exists. Additionally, it no longer prevents the use of multithreaded primitives within the “peach” operation.
It also introduces a work-stealing algorithm technique in which idle processors can intelligently acquire tasks from busy ones. This marks a departure from the previous method of pre-allocating chunks to each thread, and with it, better utilization of CPU cores, which in our own test have resulted in significant reductions in processing time.
q)\s
8i
/Before: kdb+ 4.0
q)\t (inv peach)peach 2 4 1000 1000#8000000?1.
4406
/After: kdb+ 4.1
q)\t (inv peach)peach 2 4 1000 1000#8000000?1.
2035
Network Improvements
For large enterprise deployments and cloud enabled workloads, unlimited network connections offer reliability and robust performance at an unprecedented scale. With kdb+ 4.1, user-defined shared libraries now extend well beyond 1024 file descriptors for event callbacks, and HTTP Persistent Connections elevate efficiency and responsiveness of data interactions, replacing the one-and-done approach previously used to reduce latency and optimize resource utilization.
Multithreaded Data Loading
The CSV load, fixed-width load (0:), and binary load (1:) functionalities are now multithreaded, signifying a significant leap in performance and efficiency, this is particularly beneficial for handling large datasets which in our own tests have resulted in a 50% reduction in ingestion times.
Socket Performance
Socket operations have also been enhanced, resulting in a five-fold increase in throughput when tested against previous versions. With kdb+ 4.1 users can expect a significant boost in overall performance and a tangible difference, when dealing with high volume connections.
q)h:hopen `:tcps://localhost:9999
q)h ".z.w"
1004i
/Before: kdb+ 4.0
q)\ts:10000 h "2+2"
1508 512
/After: kdb+ 4.1
q)\ts:10000 h "2+2"
285 512
Enhanced TLS Support and Updated OpenSSL
Enhanced TLS and Updated OpenSSL Support guarantee compliance and safeguard sensitive real-time data exchanges. With kdb 4.1 OpenSSL 1.0, 1.1.x, and 3.x, coupled with dynamic searching for OpenSSL libraries and TCP and UDS encryption, offers a robust solution for industries where data integrity and confidentiality are non-negotiable.
Furthermore, TLS messaging can now be utilized on threads other than the main thread. This allows for secure Inter-Process Communication (IPC) and HTTP operations in multithreaded input queue mode. Additionally, HTTP client requests and one-shot sync messages within secondary threads are facilitated through “peach”.
More Algorithms for At-Rest Compression
With the incorporation of advanced compression algorithms, kdb+ 4.1 ensures maximized storage efficiency without compromising data access speed. This provides a strategic advantage when handling extensive datasets.
New q Language Features
Kdb+ 4.1 introduces several improvements to the q language that will help to streamline your code.
- Dictionary Literal Syntax
With dictionary literals, you can concisely define dictionaries. For instance, for single element dictionaries you no longer need to enlist. Compareq)enlist[`aaa]!enlist 123 / 4.0 aaa| 123With
q)([aaa:123]) / 4.1 aaa| 123This syntax follows rules consistent with list and table literal syntax.
q)([0;1;2]) / implicit key names assigned when none defined x | 0 x1| 1 x2| 2 q)d:([a:101;b:]);d 102 / missing values create projections a| 101 b| 102 q)d each`AA`BB`CC a b ------ 101 AA 101 BB 101 CC - Pattern Matching
Assignment has been extended so the left-hand side of the colon (:) can now be a pattern./Traditional Method q)a:1 / atom /Using new method to assign b as 2 and c as 3 q)(b;c):(2;3) / list /Pattern matching on dictionary keys q)([four:d]):`one`two`three`four`five!1 2 3 4 5 / dictionary /Assigning e to be the third column x2 q)([]x2:e):([]1 2;3 4;5 6) / table q)a,b,c,d,e 1 2 3 4 5 6Before assigning any variables, q will ensure left and right values match.
q)(1b;;x):(1b;`anything;1 2 3) / empty patterns match anything q)x 1 2 3Failure to match will throw an error without assigning.
q)(1b;y):(0b;3 2 1) 'match q)y 'y - Type checking
While we’re checking patterns, we could also check types./Checks if surname is a symbol q)(surname:`s):`simpson /Checks if age is a short q)(name:`s;age:`h):(`homer;38h) /Type error triggered as float <> short q)(name:`s;age:`h):(`marge;36.5) / d'oh 'type q)name,surname / woohoo! `homer`simpsonAnd check function parameters too.
q)fluxCapacitor:{[(src:`j;dst:`j);speed:`f]$[speed<88;src;dst]} q)fluxCapacitor[1955 1985]87.9 1955 q)fluxCapacitor[1955 1985]88 'type q)fluxCapacitor[1955 1985]88.1 / Great Scott! 1985 - Filter functions
We can extend this basic type checking to define our own ‘filter functions’ to run before assignment.
/ return the value (once we're happy) q)tempCheck:{$[x<0;' "too cold";x>40;'"too hot" ;x]} q)c2f:{[x:tempCheck]32+1.8*x} q)c2f -4.5 'too cold q)c2f 42.8 'too hot q)c2f 20 / just right 68fWe can use filter functions to change the values that we’re assigning.
q)(a;b:10+;c:100+):1 2 3 q)a,b,c 1 12 103Amend values at depth without assignment.
q)addv:{([v:(;:x+;:(x*10)+)]):y} q)addv[10;([k:`hello;v:1 2 3])] k| `hello v| 1 12 103Or even change the types.
q)chkVals:{$[any null x:"J"$ "," vs x;'`badData;x]} q)sumVals:{[x:chkVals]sum x} q)sumVals "1,1,2,3,5,8" 20 q)sumVals "8,4,2,1,0.5" 'badData
Happy Coding
We hope you are as excited as we are about the possibilities these enhancements bring to your development toolkit. From parallel processing and network scalability to streamlined data loading, secure transmissions, and optimized storage, our commitment is to empower you with tools that make your coding life more efficient and enjoyable.
We invite you to dive in, explore, and unlock the full potential of kdb+ 4.1. Download our free Personal Edition today.
Happy coding!
Related Resources
Machine Learning Toolkit Update: Cross-Validation and ML Workflow in kdb+
By Conor McCarthy
The KX machine learning team has an ongoing project of periodically releasing useful machine learning libraries and notebooks for kdb+. These libraries and notebooks act as a foundation to our users, allowing them to use the ideas presented and the code provided to access the exciting world of machine learning with KX.
This release, which is the second in a series of releases in 2019, relates to the areas of cross-validation and standardized code distribution procedures for incorporating both Python and q distribution. Such procedures are used in feature creation through the FRESH algorithm and cross-validation within kdb+/q.
The toolkit is available in its entirety on the KX GitHub with supporting documentation on the Machine Learning Toolkit page of the KX Developers’ site.
As with all the libraries released from the KX machine learning team, the machine learning Toolkit (ML-Toolkit) and its constituent sections are available as open source, Apache 2 software.
Background
The primary purpose of this library is to provide kdb+/q users with access to commonly-used machine learning functions for preprocessing data, extracting features and scoring results.
This latest release expands on the scoring and feature extraction aspects of the toolkit, by introducing two new areas of functionality and improving functions contained in the machine learning toolkit:
- Cross-validation and grid search functions to test the ability of a model to generalize to new or increased volumes of data.
- A framework for transparently distributing jobs to worker processes, including serialized Python algorithms.
- .ml.df2tab and .ml.tab2df now support time and date types for conversion which improves function performance as incompatible types are no longer returned as foreigns.
Technical description
Cross-Validation
Cross-validation is used to gain a statistical understanding of how well a machine learning model generalizes to independent datasets. This is important in limiting overfitting and selection bias, especially when dealing with small datasets. A variety of methods exist for cross-validation, with the following implemented in this release:
- Stratified K-Fold Cross-Validation
- Shuffled K-Fold Cross-Validation
- Sequentially Split K-Fold Cross-Validation
- Roll-Forward Time-Series Cross-Validation
- Chain-Forward Time-Series Cross-Validation
- Monte-Carlo Cross-Validation
All of the aforementioned methods have been implemented in kdb+/q and are documented fully on code.staging.kx.com here. For each of these methods, a grid search procedure has also been implemented allowing users to find the best set of hyperparameters to use with a specific machine learning algorithm.
The roll-forward and chain-forward methods have particular relevance to time-series data. These methods maintain a strict order where the training sets precede the validation sets, ensuring that future observations are not used in constructing a forecast model. A graphical representation of each is provided below.
Roll-forward cross-validation
This method tests the validity of a model over time with equisized training and testing sets, while enforcing that the model only test on future data.

Image 1. Roll-forward validation
Chain-forward cross-validation
This method tests the ability of a model to generalize when retrained on increasingly larger volumes of data. It provides insight into how the accuracy of predictions is affected when expanding volumes of training data are used.

Image 2. Chain-forward validation
Full documentation on the cross-validation functions can be found here.
Standardized multiprocess distribution framework
A framework has been developed to transparently distribute jobs to worker processes in kdb+/q. This framework supports distribution of both Python and q code, this has been incorporated into the FRESH and cross-validation libraries and is also available as a standalone library. Distribution works as follows:
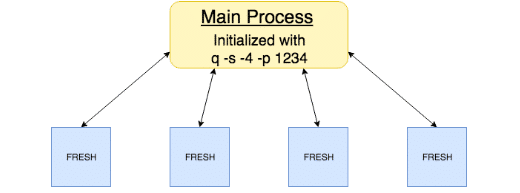
- Initialize a q process with four workers on a user-defined central port.
$ q ml/ml.q -s -4 -p 1234- Load the library ( .ml.loadfile`:util/mproc.q) into the main process.
- Call .ml.mproc.init to create and initialize worker processes, e.g. to initialize workers with the FRESH library, call
.ml.mproc.init[abs system"s"]enlist".ml.loadfile`:fresh/init.q"Which results in the following architecture
Within the toolkit, work involving both the FRESH and cross-validation procedures will be automatically peached if the console has been started with a defined number of worker processes and main port. The procedures can be initialized by running either of the following:
FRESH process
q)\l ml/ml.q // initialize ml.q on the console
q).ml.loadfile`:fresh/init.q // initialize freshCross-Validation process
q)\l ml/ml.q // initialize ml.q on the console
q).ml.loadfile`:xval/init.q // initialize cross-validationWhile general purpose in nature, this framework is particularly important when distributing Python.
The primary difficulty with Python distribution surrounds Python’s use of a Global Interpreter Lock (GIL). This limits the execution of Python bytecode to one thread at a time, thus making distributing Python more complex than its q counterpart. We can subvert this by either wrapping the Python functionality within a q lambda or by converting the Python functionality to a byte stream using Python ‘pickle’ and passing these to the worker processes for execution. Both of these options are possible within the framework outlined here.
If you would like to further investigate the uses of the machine learning toolkit, check out the machine learning toolkit on the KX GitHub to find the complete list of the functions that are available in the toolkit. You can also use Anaconda to integrate into your Python installation to set up your machine learning environment, or you build your own which consists of downloading kdb+, embedPy and JupyterQ. You can find the installation steps here.
Please do not hesitate to contact ai@devweb.kx.com if you have any suggestions or queries.


